Gen4565645644 AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen AdministrationGen Administrationv
ManagementManagementManagementManagementManagementManagementManagementManagement
ManagementManagementManagementManagement4545
ManagementManagementManagementManagementManagementManagementManagementManagement
ManagementManagementManagementManagementManagement
testsdfsdfdsfds
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Nunc ac faucibus odio. Vestibulum neque massa, scelerisque sit amet ligula eu, congue molestie mi. Praesent ut varius sem. Nullam at porttitor arcu, nec lacinia nisi. Ut ac dolor vitae odio interdum condimentum. Vivamus dapibus sodales ex, vitae malesuada ipsum cursus convallis. Maecenas sed egestas nulla, ac condimentum orci. Mauris diam felis, vulputate ac suscipit et, iaculis non est. Curabitur semper arcu ac ligula semper, nec luctus nisl blandit. Integer lacinia ante ac libero lobortis imperdiet. Nullam mollis convallis ipsum, ac accumsan nunc vehicula vitae. Nulla eget justo in felis tristique fringilla. Morbi sit amet tortor quis risus auctor condimentum. Morbi in ullamcorper elit. Nulla iaculis tellus sit amet mauris tempus fringilla. Maecenas mauris lectus, lobortis et purus mattis, blandit dictum tellus. Maecenas non lorem quis tellus placerat varius. Nulla facilisi. Aenean congue fringilla justo ut aliquam. Mauris id ex erat. Nunc vulputate neque vitae justo facilisis, non condimentum ante sagittis. Morbi viverra semper lorem nec molestie. Maecenas tincidunt est efficitur ligula euismod, sit amet ornare est vulputate. 12 10 0 2 4 6 8 Row 1 Row 2 Row 3 Row 4 Column 1 Column 2 Column 3 In non mauris justo. Duis vehicula mi vel mi pretium, a viverra erat efficitur. Cras aliquam est ac eros varius, id iaculis dui auctor. Duis pretium neque ligula, et pulvinar mi placerat et. Nulla nec nunc sit amet nunc posuere vestibulum. Ut id neque eget tortor mattis tristique. Donec ante est, blandit sit amet tristique vel, lacinia pulvinar arcu. Pellentesque scelerisque fermentum erat, id posuere justo pulvinar ut. Cras id eros sed enim aliquam lobortis. Sed lobortis nisl ut eros efficitur tincidunt. Cras justo mi, porttitor quis mattis vel, ultricies ut purus. Ut facilisis et lacus eu cursus. In eleifend velit vitae libero sollicitudin euismod. Fusce vitae vestibulum velit. Pellentesque vulputate lectus quis pellentesque commodo. Aliquam erat volutpat. Vestibulum in egestas velit. Pellentesque fermentum nisl vitae fringilla venenatis. Etiam id mauris vitae orci maximus ultricies. Cras fringilla ipsum magna, in fringilla dui commodo a. Lorem ipsum Lorem ipsum Lorem ipsum 1 In eleifend velit vitae libero sollicitudin euismod. Lorem 2 Cras fringilla ipsum magna, in fringilla dui commodo a. Ipsum 3 Aliquam erat volutpat. Lorem 4 Fusce vitae vestibulum velit. Lorem 5 Etiam vehicula luctus fermentum. Ipsum Etiam vehicula luctus fermentum. In vel metus congue, pulvinar lectus vel, fermentum dui. Maecenas ante orci, egestas ut aliquet sit amet, sagittis a magna. Aliquam ante quam, pellentesque ut dignissim quis, laoreet eget est. Aliquam erat volutpat. Class aptent taciti sociosqu ad litora torquent per conubia nostra, per inceptos himenaeos. Ut ullamcorper justo sapien, in cursus libero viverra eget. Vivamus auctor imperdiet urna, at pulvinar leo posuere laoreet. Suspendisse neque nisl, fringilla at iaculis scelerisque, ornare vel dolor. Ut et pulvinar nunc. Pellentesque fringilla mollis efficitur. Nullam venenatis commodo imperdiet. Morbi velit neque, semper quis lorem quis, efficitur dignissim ipsum. Ut ac lorem sed turpis imperdiet eleifend sit amet id sapien
RapidMiner: A No-Code Data Science Platform
What is RapidMiner?
RapidMiner is a data science platform that includes data mining tools and is popular with data scientists of all skill levels:
RapidMiner has a visual programming environment that supports the entire data science process, including data preparation, machine learning, data mining, and model deployment.
RapidMiner has a user-friendly interface that makes it appealing to non-technical users.
RapidMiner's data mining tools include operators for association rule learning, clustering, text mining, and anomaly detection.
RapidMiner's data preparation tools include operators for data cleaning, wrangling, and feature engineering.
RapidMiner's machine learning tools include operators for supervised learning, unsupervised learning, and reinforcement learning.
RapidMiner's model deployment tools help you deploy predictive analytics models to production environments
RapidMiner is a data science platform that provides a visual programming environment for developing and deploying predictive analytics applications. It is a popular choice for data scientists of all skill levels, but it is especially appealing to non-technical users due to its user-friendly interface and wide range of features.
RapidMiner offers a variety of features that support the entire data science process, from data preparation to modelling to validation. These features include:
RapidMiner also offers a number of features that make it particularly appealing to non-technical users, such as:
RapidMiner is a powerful and versatile data science platform that is well-suited for users of all skill levels. Its user-friendly interface, wide range of features, and pre-built operators make it a particularly good choice for non-technical users who are looking to get started with data science.
Here are some of the benefits of using RapidMiner:
Getting Started with RapidMiner
Installation:
Familiarize Yourself with the Interface:

Interface
Repository Panel
The Repository Panel in RapidMiner Studio is essentially the central storage area for all the objects you create or import. Here’s what it contains:
Users manage their projects by organizing these items into folders within the Repository Panel, making it easier to navigate and manage large numbers of files.
Process Panel
The Process Panel is where you design and build your data analysis workflows in RapidMiner Studio. This panel represents the workspace or canvas for crafting an analytical process. Here’s how it works:
Operators Panel
The Operators Panel is a comprehensive library of all the operators available in RapidMiner. It’s categorized to help you find the right tool for the job:
Parameters Panel
When you select an operator in the Process Panel, the Parameters Panel displays settings that can be adjusted to customize the operator’s behavior:
Importing Data

Importing data
Preprocessing Data
Include more operators for data preprocessing(based on your data set and the requirements

More about Operators
RapidMiner operators are the building blocks of data science workflows. They are responsible for performing specific tasks on data, such as cleaning, transforming, and modelling. Operators are connected together to create workflows that perform complex data analysis and machine learning tasks.
Operators have a specific structure, which is defined by the following parameters:
Operators can be classified into different types, such as:
RapidMiner also offers a number of special operators, such as:
Operators can be combined together to create complex data science workflows. For example, a workflow might include operators for data cleaning, feature engineering, model training, and model evaluation.
Here is an example of a simple RapidMiner workflow:
Read File -> Select Attributes -> Normalize -> Train Model -> Evaluate Model
This workflow reads a data file, selects a subset of attributes, normalizes the data, trains a machine learning model, and evaluates the model.
Operators can be organized into groups and sub-groups to make them easier to manage. For example, the machine learning operators could be organized into a group called “Machine Learning”, and the data preparation operators could be organized into a group called “Data Preparation”.
Operators can also be parameterized to customize their behaviour. For example, the “Normalize” operator has a parameter called “Normalization Method” that can be used to choose the normalization method to use.
RapidMiner’s operator architecture is flexible and powerful. It allows users to create complex data science workflows without having to write any code.
Once you have dragged and dropped operators into the Process Panel in RapidMiner, you’ll need to connect them to build a data analysis workflow. Here’s how you can complete the task using ports and other features:
Connecting Operators with Ports
Each operator has input and output ports, which appear as small squares or rectangles on the left (input) and right (output) sides of the operator’s block. To build a functioning process, you must connect the output port of one operator to the input port of the subsequent operator in your workflow.
Here’s a step-by-step guide to connecting operators:

Connecting Ports

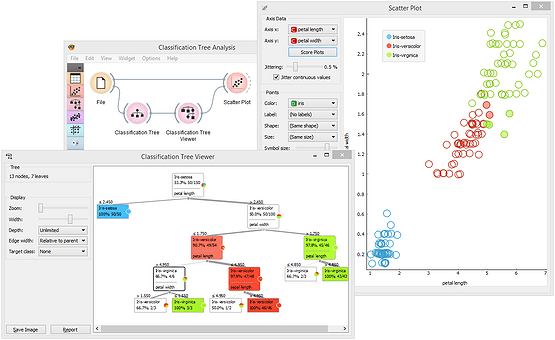
Results
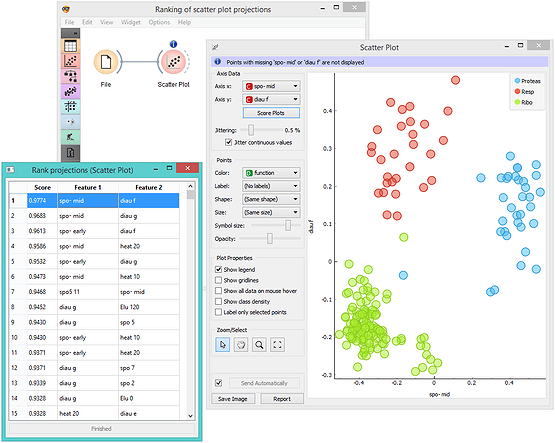
Here’s the algorithm selection. Rapidminer will serve several popular classification algorithms for us to choose from.
This is the list of algorithms you can choose:
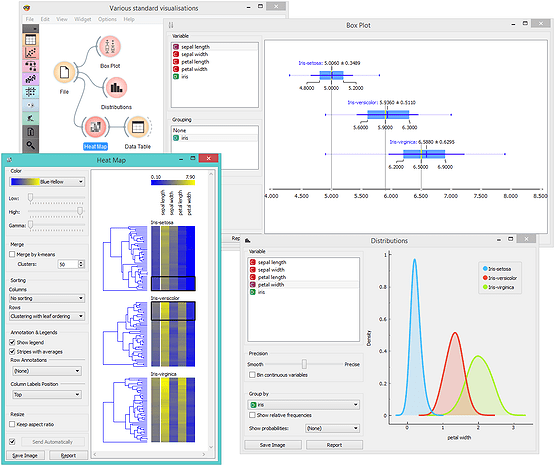
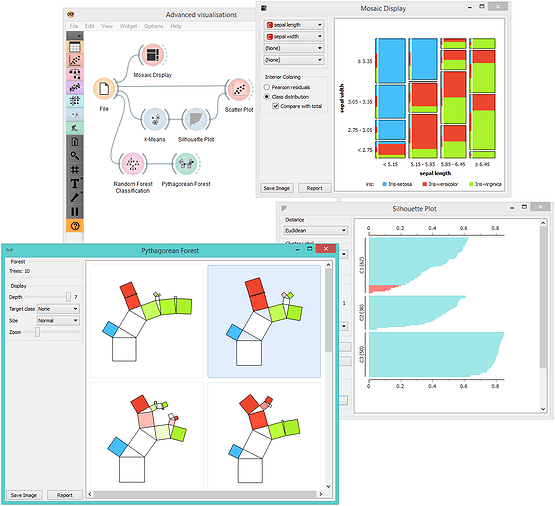
RapidMiner is a comprehensive data science platform that caters to both seasoned data scientists and beginners. Here are its key features:
Using RapidMiner: A Practical Example
Let’s walk through a simple case study using RapidMiner:
-----------------------------------------------------------------------------------------------------------------------------------
What is Orange?

Orange Data Mining:
Orange supports a flexible domain for developers, analysts, and data mining specialists. Python, a new generation scripting language and programming environment, where our data mining scripts may be easy but powerful. Orange employs a component-based approach for fast prototyping. We can implement our analysis technique simply like putting the LEGO bricks, or even utilize an existing algorithm.
What are Orange components for scripting Orange widgets for visual programming?. Widgets utilize a specially designed communication mechanism for passing objects like classifiers, regressors, attribute lists, and data sets permitting to build easily rather complex data mining schemes that use modern approaches and techniques.
Orange Widgets:

Orange scripting:
Key Features of Orange:


Example: Sentiment Analysis Using Orange
Let’s walk through a practical example: sentiment analysis on a dataset of boat headphone reviews. We’ll use Orange’s no-code approach:
Remember, Orange simplifies the entire process, allowing you to focus on insights rather than code.
Orange is a visual programming tool for data mining, machine learning, and data analysis. It's made up of components called widgets that can be combined to create workflows. Orange is user-friendly and has a visual interface that's suitable for beginners and experienced data miners alike.
Here are some examples of what you can do with Orange:
·
Introducing a No-Code tool for Data Scientists to teach beginners how to create their first machine learning models without coding experience.

Nowadays everyone is talking about Artificial Intelligence and Data Science, especially after the latest results obtained by the Generative AI.
There are plenty of sources from which to acquire information useful for learning the basics of AI: newspaper articles, posts on various social networks, video interviews with experts in the field, and much more.
However, going from theory to practice is not so trivial, especially if you do not have a good foundation in computer programming.
Imagine having to use this tool to teach a person unfamiliar with the basics of data science and artificial intelligence to develop his/her first model.
It would be utopian to think of obtaining results by starting with the use of this tool without giving a minimum theoretical basis on these topics.
Based both on the main features of Orange Data Mining and on the practical experience gained from preparing and delivering artificial intelligence courses for non-experts, these are the basic aspects to be considered as theoretical pre-requisites:
Ok, now you are ready: let’s install and configure our no-code tool!
How to install and configure Orange Data Mining
Orange Data Mining is a freely available visual programming software package that enables users to engage in data visualization, data mining, machine learning, and data analysis.
There are different ways to install this tool.
The easiest one is to access to the official website and download the Standalone installer.
If you already have the anaconda platform installed on your PC, you can also install orange as a package with the following commands:
Orange Data Mining Interface
Well done!
Now you can start exploring Orange Data Mining.
Based on the installation mode there are two different ways to open the tool:
Opening the tool interface will look like this.

Figure 1 — Orange Data Mining Canvas
The popup enables you to initiate a new workflow from scratch or open an existing one.
Upon clicking the ‘New’ icon, a blank canvas is revealed.
To start populating this empty canvas, utilize the widgets [2], which serve as the computational units in Orange Data Mining.
Access them through the explorer bar on the left, conveniently organized into subgroups based on their functions:
To employ these widgets, simply drag them from the explorer bar onto the canvas.
As an example, try dragging the File widget into the Data group; this widget aids in loading data from your hard drive.
The Orange Data Mining Interface will then adopt the following appearance:

Figure 2 — Orange Data Mining Widgets
You’ll notice that the widget features a dashed grey arch.
By clicking on it and dragging the mouse to the right, a line emerges from the widget. This line serves to connect two different widgets and kickstart the creation of your initial workflow.
The arch’s position relative to the widget provides insights into the widget’s requirements:
Armed with this information, you’re ready to delve into Orange!
To facilitate a better understanding of how to leverage this tool for developing a machine learning model, let’s dive into an example.
Load and Transform Data
You’ll be working with the Kaggle challenge titled ‘Red Wine Quality’ accessible at this link.
This dataset encompasses the characteristics of 1600 red and white variants of Portuguese ‘Vinho Verde’ wine, with the output variable representing a score between 0 and 10.
Our goal is to develop a classification model capable of predicting the score based on input features such as fixed acidity and citric acid.
To begin, download the dataset from the provided link and import it into Orange.
In the Data widget area, numerous options are available for loading and storing data.
In this instance, you can drag the CSV File Import widget onto our blank sheet. Double-click on it and select the ‘Red Wine Quality’ CSV file.

Figure 3 — Import a CSV in a workflow
Orange demonstrates the ability to automatically identify the CSV delimiter (in this case, a comma) and the column type for each column.
If any discrepancies are noted, you can address them by selecting a specific column and adjusting its type. After completing these adjustments, click ‘OK’ to close the widget pop-up.
To effectively utilize the dataset, it’s essential to establish a connection between the CSV input files and a widget designed for storing data in a tabular format. Drag the Data Table widget onto the canvas and connect the two widgets, as illustrated in the Figure 4.

Figure 4 — Create a Data Table
You can now explore into the dataset through some fundamental visualizations. Navigate to the explorer bar and locate the Visualize group. Drag and drop the Distributions, Scatter Plot, and Violin Plot widgets onto the canvas. Connect each of them to the Data Table for a comprehensive exploration.

Figure 5 — Basics of Data Visualization in Orange Data Mining
Take note of the text located above each link: to ensure that all data is visualized in your plots, it’s essential to double-click on the text and modify the link, as shown in the image below.

Figure 6 — How to use all data or a portion of a dataset
The Selected Data option proves useful when you wish to visualize (or, more broadly, inspect the results of your workflow) for only a subset of your dataset.
You can make this data selection by double-clicking on the Data Table and choosing a range of rows in a style reminiscent of Excel, as you can see in the Figure 7.

Figure 7 — Select a portion of a dataset
Now, let’s generate the target variable based on the quality feature. Suppose you want to setup a multiclass classification score, categorizing wine as bad if the quality is less than or equal to 4, medium for qualities between 5 and 6, and excellent otherwise.
To create the target column, use the Feature Constructor widget located in the Transform group (the widget has been renamed in the latest version of Orange to ‘Formula’).
Link the Data Table to this widget, and setting up the target column involves the following steps:

Figure 8 — The Feature Constructor tool
To view the newly created column, connect a Data Table widget to the Feature Constructor, and double-click on it to inspect the added column.

Figure 9 — Data Preparation with Orange Data Mining
This is merely an illustrative example, so let’s move on. It’s worth noting that there are additional useful widgets in the Transform group for data preprocessing, such as merging and concatenating data, converting a column to continuous or discrete values, imputing missing values, and more.
Train and Evaluate the Models
First of all: although you’ve generated our ‘score’ variable, you haven’t designated it as the target yet.
The solution lies in the Select Column widget that you can see in the Figure 10.

Figure 10 — Select columns for a Machine Learning model
Now, our objective is to partition the dataset into Training Data and Test Data.
The Data Sampler widget facilitates this split, offering various methods and options (such as Stratify sample, crucial for addressing imbalanced classification problems).

Figure 11 — Split Train and Test Dataset
Now, let’s proceed to the modeling phase.
The most straightforward approach is to utilize the Test and Score widget within the Evaluate group.
This widget requires the following inputs:

Figure 12 — Test and Score different models
All the components are linked together. By opening the Test and Score widget, you can choose various training and test options and evaluate the performance of the tested models.

Figure 13 — Evaluate model performances
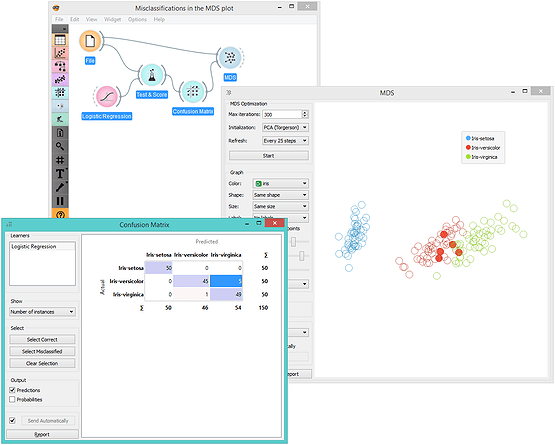
You can also examine the confusion matrix by connecting the output of the Test and Score widget to the Confusion Matrix widget.

Figure 14 — Visualize the Confusion Matrix
Task accomplished! The Figure 15 shows the complete (and simple) workflow that you have constructed step by step.

Figure 15 — The final workflow
Useful Extensions
The standard installation of Orange includes default widgets, but additional extensions are available for installation. The process of installing add-ons varies depending on the initial Orange installation type:
Explore the complete widget catalog at this link.
Areas of application, advantages, limitations, and other tools
Orange Data Mining, with its user-friendly interface and open-source nature, presents several advantages that cater to a diverse range of users. Its visual programming interface stands out as an intuitive tool, allowing users with varying technical backgrounds to seamlessly create data analysis workflows. The richness of pre-built components, spanning data preprocessing, machine learning, and visualization, further enhances its appeal, providing users with a comprehensive toolkit for various data-related tasks.
Indeed, Orange is widely employed in academic settings to introduce students to the realms of data mining and machine learning, leveraging its user-friendly interface to make complex concepts more accessible.
However, Orange does have limitations. Scalability can be a concern, particularly when handling large datasets or complex workflows. The tool may not exhibit the same level of performance as some commercial alternatives in such scenarios. Additionally, while Orange offers a diverse array of machine learning algorithms, it might not incorporate the most cutting-edge or specialized models found in some proprietary tools.
In conclusion, Orange Data Mining stands out as a versatile and accessible tool, particularly for educational purposes and smaller to medium-sized datasets. Its strengths in visualization and community collaboration make it a valuable asset, but potential users should consider its scalability limitations and the learning curve associated with advanced features. The choice of Orange depends on the specific needs, preferences, and expertise of the user, with recognition of its contributions to the open-source data mining landscape.
------------------------------------------------------------------------------------------------------------------------
Data Mining in R: An Overview
The Power of R for Data Mining
R is a widely used programming language and environment for statistical computing and graphics. It provides a vast collection of packages and libraries specifically designed for data mining tasks. Here are some key reasons why R is a popular choice for data mining −
Data Mining Techniques in R
R offers a wide range of data mining techniques that can be applied to different types of datasets. Here are some commonly used techniques −
Practical Examples and Use Cases
Data mining with R finds applications in various domains. Here are a few examples −
R Programming Tutorial

R Programming Tutorial is designed for both beginners and professionals.
R is a software environment which is used to analyze statistical information and graphical representation. R allows us to do modular programming using functions.
What is R Programming
"R is an interpreted computer programming language which was created by Ross Ihaka and Robert Gentleman at the University of Auckland, New Zealand." The R Development Core Team currently develops R. It is also a software environment used to analyze statistical information, graphical representation, reporting, and data modeling. R is the implementation of the S programming language, which is combined with lexical scoping semantics.
R not only allows us to do branching and looping but also allows to do modular programming using functions. R allows integration with the procedures written in the C, C++, .Net, Python, and FORTRAN languages to improve efficiency.
In the present era, R is one of the most important tool which is used by researchers, data analyst, statisticians, and marketers for retrieving, cleaning, analyzing, visualizing, and presenting data.
History of R Programming
The history of R goes back about 20-30 years ago. R was developed by Ross lhaka and Robert Gentleman in the University of Auckland, New Zealand, and the R Development Core Team currently develops it. This programming language name is taken from the name of both the developers. The first project was considered in 1992. The initial version was released in 1995, and in 2000, a stable beta version was released.

The following table shows the release date, version, and description of R language:
|
Version-Release |
Date |
Description |
|
0.49 |
1997-04-23 |
First time R's source was released, and CRAN (Comprehensive R Archive Network) was started. |
|
0.60 |
1997-12-05 |
R officially gets the GNU license. |
|
0.65.1 |
1999-10-07 |
update.packages and install.packages both are included. |
|
1.0 |
2000-02-29 |
The first production-ready version was released. |
|
1.4 |
2001-12-19 |
First version for Mac OS is made available. |
|
2.0 |
2004-10-04 |
The first version for Mac OS is made available. |
|
2.1 |
2005-04-18 |
Add support for UTF-8encoding, internationalization, localization etc. |
|
2.11 |
2010-04-22 |
Add support for Windows 64-bit systems. |
|
2.13 |
2011-04-14 |
Added a function that rapidly converts code to byte code. |
|
2.14 |
2011-10-31 |
Added some new packages. |
|
2.15 |
2012-03-30 |
Improved serialization speed for long vectors. |
|
3.0 |
2013-04-03 |
Support for larger numeric values on 64-bit systems. |
|
3.4 |
2017-04-21 |
The just-in-time compilation (JIT) is enabled by default. |
|
3.5 |
2018-04-23 |
Added new features such as compact internal representation of integer sequences, serialization format etc. |
Features of R programming
R is a domain-specific programming language which aims to do data analysis. It has some unique features which make it very powerful. The most important arguably being the notation of vectors. These vectors allow us to perform a complex operation on a set of values in a single command. There are the following features of R programming:
Why use R Programming?
There are several tools available in the market to perform data analysis. Learning new languages is time taken. The data scientist can use two excellent tools, i.e., R and Python. We may not have time to learn them both at the time when we get started to learn data science. Learning statistical modeling and algorithm is more important than to learn a programming language. A programming language is used to compute and communicate our discovery.
The important task in data science is the way we deal with the data: clean, feature engineering, feature selection, and import. It should be our primary focus. Data scientist job is to understand the data, manipulate it, and expose the best approach. For machine learning, the best algorithms can be implemented with R. Keras and TensorFlow allow us to create high-end machine learning techniques. R has a package to perform Xgboost. Xgboost is one of the best algorithms for Kaggle competition.
R communicate with the other languages and possibly calls Python, Java, C++. The big data world is also accessible to R. We can connect R with different databases like Spark or Hadoop.
In brief, R is a great tool to investigate and explore the data. The elaborate analysis such as clustering, correlation, and data reduction are done with R.
Comparison between R and Python
Data science deals with identifying, extracting, and representing meaningful information from the data source. R, Python, SAS, SQL, Tableau, MATLAB, etc. are the most useful tools for data science. R and Python are the most used ones. But still, it becomes confusing to choose the better or the most suitable one among the two, R and Python.
|
Comparison Index |
R |
Python |
|
Overview |
"R is an interpreted computer programming language which was created by Ross Ihaka and Robert Gentleman at the University of Auckland, New Zealand ." The R Development Core Team currently develops R. R is also a software environment which is used to analyze statistical information, graphical representation, reporting, and data modeling. |
Python is an Interpreted high-level programming language used for general-purpose programming. Guido Van Rossum created it, and it was first released in 1991. Python has a very simple and clean code syntax. It emphasizes the code readability and debugging is also simple and easier in Python. |
|
Specialties for data science |
R packages have advanced techniques which are very useful for statistical work. The CRAN text view is provided by many useful R packages. These packages cover everything from Psychometrics to Genetics to Finance. |
For finding outliers in a data set both R and Python are equally good. But for developing a web service to allow peoples to upload datasets and find outliers, Python is better. |
|
Functionalities |
For data analysis, R has inbuilt functionalities |
Most of the data analysis functionalities are not inbuilt. They are available through packages like Numpy and Pandas |
|
Key domains of application |
Data visualization is a key aspect of analysis. R packages such as ggplot2, ggvis, lattice, etc. make data visualization easier. |
Python is better for deep learning because Python packages such as Caffe, Keras, OpenNN, etc. allows the development of the deep neural network in a very simple way. |
|
Availability of packages |
There are hundreds of packages and ways to accomplish needful data science tasks. |
Python has few main packages such as viz, Sccikit learn, and Pandas for data analysis of machine learning, respectively. |
Applications of R
There are several-applications available in real-time. Some of the popular applications are as follows:
Prerequisite
R programming is used for statistical information and data representation. So it is required that we should have the knowledge of statistical theory in mathematics. Understanding of different types of graphs for data representation and most important is that we should have prior knowledge of any programming.
Features of R – Data Science
Some of the important features of R for data science applications are:
Most common R Libraries in Data Science
Other worth mentioning R libraries:
Applications of R for Data Science
Top Companies that Use R for Data Science:
R is another tool that is popular for data mining. R is an open-source programming tool developed by Bell Laboratories (formerly AT&T, now Lucent Technologies). Data scientists, machine learning engineers, and statisticians for statistical computing, analytics, and machine learning tasks prefer R
1. Getting Started with R:
2. Commonly Used R Packages for Data Mining:
Here are some essential R packages for data mining:
3. Data Preparation (Data Preprocessing):
Before diving into data mining, you’ll need to prepare your data. Here are some common data preprocessing tasks in R:
4. Example: Sentiment Analysis Using R:
Let’s walk through a practical example—sentiment analysis on a dataset of product reviews:
Remember, R is not only a programming language but also a powerful environment for data mining.
Clustering is a technique used in data mining and machine learning to group similar data points together based on their attributes. It is an unsupervised learning method, meaning it doesn’t require predefined classes or labels. Clustering helps identify patterns and relationships in data, making it easier to analyze and understand large datasets.
Here are the main types of clustering methods in data mining:
What is Clustering?
Cluster Analysis separates data into groups, usually known as clusters. If meaningful groups are the objective, then the clusters catch the general information of the data. Some time cluster analysis is only a useful initial stage for other purposes, such as data summarization. In the case of understanding or utility, cluster analysis has long played a significant role in a wide area such as biology, psychology, statistics, pattern recognition machine learning, and mining.
The below diagram explains the working of the clustering algorithm. We can see the different fruits are divided into several groups with similar properties.

Clustering is the process of making a group of abstract objects into classes of similar objects.
Clustering is a technique used in machine learning to group similar data points together. It is an unsupervised learning method that does not require predefined classes or prior information.
Clustering helps to identify patterns and relationships in data that might be difficult to detect through other methods.
Clustering vs Classification -Classification is a supervised learning method that involves assigning predefined classes or labels to data points based on their features or attributes. In contrast, clustering is an unsupervised learning method that groups data points based on their similarities.
Points to Remember
The main advantage of clustering over classification is that, it is adaptable to changes and helps single out useful features that distinguish different groups.
Cluster analysis, also known as clustering, is a method of data mining that groups similar data points together. The goal of cluster analysis is to divide a dataset into groups (or clusters) such that the data points within each group are more similar to each other than to data points in other groups. This process is often used for exploratory data analysis and can help identify patterns or relationships within the data that may not be immediately obvious. There are many different algorithms used for cluster analysis, such as k-means, hierarchical clustering, and density-based clustering. The choice of algorithm will depend on the specific requirements of the analysis and the nature of the data being analyzed.
Cluster Analysis is the process to find similar groups of objects in order to form clusters. It is an unsupervised machine learning-based algorithm that acts on unlabelled data. A group of data points would comprise together to form a cluster in which all the objects would belong to the same group.
The given data is divided into different groups by combining similar objects into a group. This group is nothing but a cluster. A cluster is nothing but a collection of similar data which is grouped together.
For example, consider a dataset of vehicles given in which it contains information about different vehicles like cars, buses, bicycles, etc. As it is unsupervised learning there are no class labels like Cars, Bikes, etc for all the vehicles, all the data is combined and is not in a structured manner.
Clustering is a powerful tool for data analysis that is a type of unsupervised learning that groups similar data points together based on certain criteria.
Now our task is to convert the unlabelled data to labelled data and it can be done using clusters.
The main idea of cluster analysis is that it would arrange all the data points by forming clusters like cars cluster which contains all the cars, bikes clusters which contains all the bikes, etc.
Simply it is the partitioning of similar objects which are applied to unlabelled data.
Properties of Clustering :
1. Clustering Scalability: Nowadays there is a vast amount of data and should be dealing with huge databases. In order to handle extensive databases, the clustering algorithm should be scalable. Data should be scalable, if it is not scalable, then we can’t get the appropriate result which would lead to wrong results.
2. High Dimensionality: The algorithm should be able to handle high dimensional space along with the data of small size.
3. Algorithm Usability with multiple data kinds: Different kinds of data can be used with algorithms of clustering. It should be capable of dealing with different types of data like discrete, categorical and interval-based data, binary data etc.
4. Dealing with unstructured data: There would be some databases that contain missing values, and noisy or erroneous data. If the algorithms are sensitive to such data then it may lead to poor quality clusters. So it should be able to handle unstructured data and give some structure to the data by organising it into groups of similar data objects. This makes the job of the data expert easier in order to process the data and discover new patterns.
5. Interpretability: The clustering outcomes should be interpretable, comprehensible, and usable. The interpretability reflects how easily the data is understood.
What is Clustering in Data Mining?
Clustering in data mining is a technique that groups similar data points together based on their features and characteristics. It can also be referred to as a process of grouping a set of objects so that objects in the same group (called a cluster) are more similar to each other than those in other groups (clusters). It is an unsupervised learning technique that aims to identify similarities and patterns in a dataset. Clustering algorithms typically require defining the number of clusters, similarity measures, and clustering methods. These algorithms aim to group data points together in a way that maximizes similarity within the groups and minimizes similarity between different groups, as shown in the picture below.
Clustering techniques in data mining can be used in various applications, such as image segmentation, document clustering, and customer segmentation. The goal is to obtain meaningful insights from the data and improve decision-making processes.
What is a Cluster?
In data mining, a cluster refers to a group of data points with similar characteristics or features. These characteristics or features can be defined by the analyst or identified by the clustering algorithm while grouping similar data points together. The data points within a cluster are typically more similar to each other than those outside the cluster. For example, in the above figure, there are 5 clusters present.
A cluster can have the following properties -
Applications of Cluster Analysis
Market segmentation is the process of dividing a market into smaller groups of customers with similar needs or characteristics. Clustering can be used to identify such groups based on various factors such as demographics, behavior, and preferences.
Once the groups are identified, targeted marketing strategies can be developed to cater to their specific needs.
Clustering is a widely used technique in data mining and has numerous applications in various fields. Some of the common applications of clustering in data mining include -
Clustering can also be used in network analysis to identify communities or groups of nodes with similar connectivity patterns.
Community detection algorithms use clustering techniques to identify such groups in social networks, biological networks, and other types of networks. This can help in understanding the structure and function of the network and in developing targeted interventions.
Clustering can be used for anomaly detection, which is the process of identifying unusual or unexpected patterns in data.
Anomalies can be detected by clustering the data and identifying points that do not belong to any cluster or belong to a small cluster. This can be useful in fraud detection, intrusion detection, and other applications where unusual behavior needs to be identified.
Clustering can be used in exploratory data analysis to identify patterns and structures in data that may not be immediately apparent. This can help in understanding the data and in developing hypotheses for further analysis.
Clustering can also be used to reduce the dimensionality of the data by identifying the most important features or variables.
In summary, clustering is a versatile technique that can be applied to various domains such as market segmentation, network analysis, anomaly detection, and exploratory data analysis. By identifying groups or patterns in data, clustering can help in developing targeted strategies, understanding network structure, detecting unusual behavior, and exploring data.
Professionals use clustering methods in a wide variety of industries to group data and inform decision-making. Some ways you might see clustering applied include the following:
Choosing cluster analyses for your data can offer many benefits. Some advantages you might experience include:
When considering advantages, it’s also important to consider disadvantages.
Limitations to be aware of include:
The following points throw light on why clustering is required in data mining −
Clustering methods can be classified into the following categories −
Suppose we are given a database of ‘n’ objects and the partitioning method constructs ‘k’ partition of data. Each partition will represent a cluster and k ≤ n. It means that it will classify the data into k groups, which satisfy the following requirements −
Points to remember −
It is used to make partitions on the data in order to form clusters. If “n” partitions are done on “p” objects of the database then each partition is represented by a cluster and n < p. The two conditions which need to be satisfied with this Partitioning Clustering Method are:
In the partitioning method, there is one technique called iterative relocation, which means the object will be moved from one group to another to improve the partitioning
Partitioning methods involve dividing the data set into a predetermined number of groups, or partitions, based on the similarity of the data points.
The most popular partitioning method is the
k-means clustering algorithm, which involves randomly selecting k initial centroids and then iteratively assigning each data point to the nearest centroid and recalculating the centroid of each group until the centroids no longer change.

Example of K-means clustering

K means is an iterative clustering algorithm that aims to find local maxima in each iteration. This algorithm works in these 5 steps:
The implementation and working of the K-Means algorithm are explained in the steps below:
Step 1: Select the value of K to decide the number of clusters (n_clusters) to be formed.
Step 2: Select random K points that will act as cluster centroids (cluster_centers).
Step 3: Assign each data point, based on their distance from the randomly selected points (Centroid), to the nearest/closest centroid, which will form the predefined clusters.
Step 4: Place a new centroid of each cluster.
Step 5: Repeat step no.3, which reassigns each datapoint to the new closest centroid of each cluster.
Step 6: If any reassignment occurs, then go to step 4; else, go to step 7.
Step 7: Finish
Partitioning Clustering Methods are widely used in data mining, machine learning, and pattern recognition. They can be used to identify groups of similar customers, segment markets, or detect anomalies in data.
Partitioning Clustering starts by selecting a fixed number of clusters and randomly assigning data points to each cluster. The algorithm then iteratively updates the cluster centroids based on the mean or median of the data points in each cluster.
Next, the algorithm reassigns each data point to the nearest cluster centroid based on a distance metric. This process is repeated until the algorithm converges to a stable solution.
Example of a K-Means cluster plot in R

Hierarchical clustering methods, as the name suggests, is an algorithm that builds a hierarchy of clusters. This algorithm starts with all the data points assigned to a cluster of their own. Then two nearest clusters are merged into the same cluster. In the end, this algorithm terminates when there is only a single cluster left.
The results of hierarchical clustering can be shown using a dendrogram. The dendrogram can be interpreted as:

At the bottom, we start with 25 data points, each assigned to separate clusters. The two closest clusters are then merged till we have just one cluster at the top. The height in the dendrogram at which two clusters are merged represents the distance between two clusters in the data space.
The decision of the no. of clusters that can best depict different groups can be chosen by observing the dendrogram. The best choice of the no. of clusters is the no. of vertical lines in the dendrogram cut by a horizontal line that can transverse the maximum distance vertically without intersecting a cluster.
In the above example, the best choice of no. of clusters will be 4 as the red horizontal line in the dendrogram below covers the maximum vertical distance AB.

This method creates a hierarchical decomposition of the given set of data objects. We can classify hierarchical methods on the basis of how the hierarchical decomposition is formed. There are two approaches here −
This approach is also known as the bottom-up approach. In this, we start with each object forming a separate group. It keeps on merging the objects or groups that are close to one another. It keep on doing so until all of the groups are merged into one or until the termination condition holds. Agglomerative Hierarchical Clustering starts by considering each data point as a separate cluster. The algorithm then iteratively merges the two closest clusters into a single cluster until all data points belong to the same cluster. The distance between clusters can be measured using different methods such as single linkage, complete linkage, or average linkage.
This approach is also known as the top-down approach. In this, we start with all of the objects in the same cluster. In the continuous iteration, a cluster is split up into smaller clusters. It is down until each object in one cluster or the termination condition holds. This method is rigid, i.e., once a merging or splitting is done, it can never be undone.
Divisive Hierarchical Clustering starts by considering all data points as a single cluster. The algorithm then iteratively divides the cluster into smaller subclusters until each data point belongs to its own cluster. The division is based on the distance between data points.
Hierarchical Clustering produces a dendrogram, which is a tree-like diagram that shows the hierarchy of clusters. The dendrogram can be used to visualize the relationships between clusters and to determine the optimal number of clusters.
Example of a Hierarchical cluster dendrogram plot in R

Here are the two approaches that are used to improve the quality of hierarchical clustering −
Density-based clustering is a type of clustering algorithm that identifies clusters as areas of high density separated by areas of low density. The goal is to group together data points that are close to each other and have a higher density than the surrounding data points.
The density-based clustering method connects the highly-dense areas into clusters, and the arbitrarily shaped distributions are formed as long as the dense region can be connected. This algorithm does it by identifying different clusters in the dataset and connects the areas of high densities into clusters. The dense areas in data space are divided from each other by sparser areas.
These algorithms can face difficulty in clustering the data points if the dataset has varying densities and high dimensions.

This method is based on the notion of density. The basic idea is to continue growing the given cluster as long as the density in the neighborhood exceeds some threshold, i.e., for each data point within a given cluster, the radius of a given cluster has to contain at least a minimum number of points.
DBSCAN and OPTICS are two common algorithms used in Density-based clustering.
Density-based clustering starts by selecting a random data point and identifying all data points that are within a specified distance (epsilon) from the point.
These data points are considered the core points of a cluster. Next, the algorithm identifies all data points within the epsilon distance from the core points and adds them to the cluster. This process is repeated until all data points have been assigned to a cluster.
Example of DBSCAN plot with Python library SciKit learn

Image source: Demo of DBSCAN clustering algorithm
In summary, Density-based clustering is a powerful type of clustering algorithm that can identify clusters based on the density of data points.
In the distribution model-based clustering method, the data is divided based on the probability of how a dataset belongs to a particular distribution. The grouping is done by assuming some distributions commonly Gaussian Distribution.

The example of this type is the Expectation-Maximization Clustering algorithm that uses Gaussian Mixture Models (GMM).

Distribution-based clustering is a type of clustering algorithm that assumes data is generated from a mixture of probability distributions and estimates the parameters of these distributions to identify clusters.
The goal is to group together data points that are more likely to be generated from the same distribution.
Expectation-Maximization (EM) and Gaussian Mixture Models (GMM) are two common algorithms used in Distribution-based clustering.
Distribution-based clustering starts by assuming that the data is generated from a mixture of probability distributions. The algorithm then estimates the parameters of these distributions (e.g., mean, variance) using the available data.
Next, the algorithm assigns each data point to the distribution that it is most likely to have been generated from. This process is repeated until the algorithm converges to a stable solution.
Grid-based clustering is a type of clustering algorithm that divides data into a grid structure and forms clusters by merging adjacent cells that meet certain criteria.
The goal is to group together data points that are close to each other and have similar values. STING and CLIQUE are two common algorithms used in Grid-based clustering.
Advantages
Grid-based clustering starts by dividing the data space into a grid structure with a fixed or hierarchical size. The algorithm then assigns each data point to the cell that it belongs to based on its location.

Next, the algorithm merges adjacent cells that meet certain criteria (e.g., minimum number of data points, minimum density) to form clusters. This process is repeated until all data points have been assigned to a cluster.
In summary, Grid-based clustering is a powerful type of clustering algorithm that can identify clusters based on a grid structure.
Connectivity-based clustering is a type of clustering algorithm that identifies clusters based on the connectivity of data points. The goal is to group together data points that are connected by a certain distance or similarity measure.
Hierarchical Density-Based Spatial Clustering (HDBSCAN) and Mean Shift are two common algorithms used in Connectivity-based clustering. HDBSCAN is a hierarchical version of DBSCAN, while Mean Shift identifies clusters as modes of the probability density function.
Connectivity-based clustering starts by defining a measure of similarity or distance between data points. The algorithm then builds a graph where each data point is represented as a node and the edges represent the similarity or distance between the nodes.
Next, the algorithm identifies clusters as connected components of the graph. This process is repeated until the desired number of clusters is obtained.
Example of HDBSCAN clustering plot in Python

Image source: HDBSCAN Docs
|
Method |
Algorithms |
Description |
|
Partitioning Clustering Methods |
K-Means, K-Medoids |
Divides data into k clusters by minimizing the sum of squared distances between data points and their assigned cluster centroid. |
|
Hierarchical Clustering |
Agglomerative Clustering, Divisive Clustering |
Agglomerative clustering builds a hierarchy of clusters by merging the two closest clusters iteratively until all data points belong to a single cluster. |
|
Density-Based Clustering |
DBSCAN, OPTICS |
Identifies clusters as areas of high density separated by areas of low density. |
|
Distribution-Based Clustering Methods |
Expectation-Maximization (EM), Gaussian Mixture Models (GMM) |
Assumes data is generated from a mixture of probability distributions and estimates the parameters of these distributions to identify clusters. |
|
Grid-Based Clustering Methods |
STING, CLIQUE |
Divides data into a grid structure and forms clusters by merging adjacent cells that meet certain criteria. |
|
Connectivity-Based Clustering Methods |
Hierarchical Density-Based Spatial Clustering (HDBSCAN), Mean Shift |
Identifies clusters by analyzing the connectivity between data points and their neighbors, allowing for the identification of clusters with varying densities and shapes. |
In summary, there are several types of clustering methods, including partitioning, hierarchical, density-based, distribution-based, grid-based, and connectivity-based methods. Each method has its own strengths and weaknesses, and the choice of which method to use will depend on the specific data set and the goals of the analysis.
In this method, a model is hypothesized for each cluster to find the best fit of data for a given model. This method locates the clusters by clustering the density function. It reflects spatial distribution of the data points.
This method also provides a way to automatically determine the number of clusters based on standard statistics, taking outlier or noise into account. It therefore yields robust clustering methods.
In this method, the clustering is performed by the incorporation of user or application-oriented constraints. A constraint refers to the user expectation or the properties of desired clustering results. Constraints provide us with an interactive way of communication with the clustering process. Constraints can be specified by the user or the application requirement.
The clustering process, in general, is based on the approach that the data can be divided into an optimal number of “unknown” groups. The underlying stages of all the clustering algorithms are to find those hidden patterns and similarities without intervention or predefined conditions. However, in certain business scenarios, we might be required to partition the data based on certain constraints. Here is where a supervised version of clustering machine learning techniques comes into play.
A constraint is defined as the desired properties of the clustering results or a user’s expectation of the clusters so formed – this can be in terms of a fixed number of clusters, the cluster size, or important dimensions (variables) that are required for the clustering process.

Usually, tree-based, Classification machine learning algorithms like Decision Trees, Random Forest, Gradient Boosting, etc. are made use of to attain constraint-based clustering. A tree is constructed by splitting without the interference of the constraints or clustering labels. Then, the leaf nodes of the tree are combined together to form the clusters while incorporating the constraints and using suitable algorithms.
Furthermore, there are different types of clustering methods, including hard clustering and soft clustering.
Hard clustering is a type of clustering where each data point is assigned to a single cluster. In other words, hard clustering is a binary assignment of data points to clusters. This means that each data point belongs to only one cluster, and there is no overlap between clusters.
Hard clustering is useful when the data points are well-separated and there is no overlap between clusters. It is also useful when the number of clusters is known in advance.
Soft clustering, also known as fuzzy clustering, is a type of clustering where each data point is assigned a probability of belonging to each cluster. Unlike hard clustering, soft clustering allows for overlapping clusters.
Soft clustering is useful when the data points are not well-separated and there is overlap between clusters. It is also useful when the number of clusters is not known in advance.
Soft clustering is based on the concept of fuzzy logic, which allows for partial membership of a data point to a cluster. In other words, a data point can belong partially to multiple clusters.

In summary, hard clustering is a binary assignment of data points to clusters, while soft clustering allows for partial membership of data points to clusters. Soft clustering is useful when the data points are not well-separated and there is overlap between clusters.
When it comes to clustering, there are a variety of techniques available to you. Some of the most commonly used clustering techniques include centroid-based, connectivity-based, and density-based clustering.
However, there are also some lesser-known techniques that can be just as effective, if not more so, depending on your specific needs. In this section, we’ll take a closer look at some of the special clustering techniques that you might want to consider using.
Spectral clustering is a technique that is often used for image segmentation, but it can also be used for other types of clustering problems. The basic idea behind spectral clustering is to transform the data into a new space where it is easier to separate the clusters.
This is done by computing the eigenvectors of the similarity matrix of the data and then using these eigenvectors to cluster the data.
Affinity propagation is a clustering technique that is based on the concept of message passing. The basic idea behind affinity propagation is to use a set of messages to determine which data points should be clustered together.
Each data point sends messages to all of the other data points, and these messages are used to update the cluster assignments. This process continues until a stable set of clusters is found.
Subspace clustering is a clustering technique that is used when the data has a complex structure that cannot be captured by traditional clustering techniques.
The basic idea behind subspace clustering is to cluster the data in different subspaces and then combine the results to obtain a final clustering. This can be done using techniques such as principal component analysis (PCA) or independent component analysis (ICA).
BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies) is a clustering technique that is designed to handle large datasets.
The basic idea behind BIRCH is to use a hierarchical clustering approach to reduce the size of the dataset and then use a clustering algorithm to cluster the reduced dataset. This can be an effective way to speed up the clustering process and make it more scalable.
OPTICS (Ordering Points To Identify the Clustering Structure) is a clustering technique that is designed to handle datasets with complex structures.
The basic idea behind OPTICS is to order the data points based on their density and then use this ordering to identify the clusters. This can be an effective way to handle datasets that have clusters of different sizes and densities.
In summary, there are a variety of special clustering techniques available to you, each with its own strengths and weaknesses. By understanding the different techniques and their applications, you can choose the one that is best suited to your specific needs.
The Clustering that appeared in the figure is all exclusive, as they give the responsibility to each object to a single cluster. There are numerous circumstances in which a point could sensibly be set in more than one cluster, and these circumstances are better addressed by non-exclusive Clustering. In general terms, an overlapping or non-exclusive Clustering is used to reflect the fact that an object can together belong to more than one group (class). For example, a person at a company can be both a trainee student and an employee of the company. A non-exclusive Clustering is also usually used if an object is "between" two or more then two clusters and could sensibly be allocated to any of these clusters. Consider a point somewhere between two of the clusters rather than make an entirely random task of the object to a single cluster. it is put in all of the clusters to "equally good" clusters.
In fuzzy Clustering, each object belongs to each cluster with a membership weight that is between 0 and 1. In other words, clusters are considered as fuzzy sets. Mathematically, a fuzzy set is defined as one in which an object is associated with any set with a weight that ranges between 0 and 1. In fuzzy Clustering, we usually set the additional constraint, and the sum of weights for each object must be equal to 1. Similarly, probabilistic Clustering systems compute the probability in which each point belongs to a cluster, and these probabilities must sum to 1. Since the membership weights or probabilities for any object sum to 1, a fuzzy or probabilistic Clustering doesn't address actual multiclass situations.
A complete Clustering allocates each object to a cluster, whereas partial Clustering does not. The inspiration for a partial Clustering is that a few objects in a data set may not belong to distinct groups. Most of the time, objects in the data set may produce outliers, noise, or "uninteresting background." For example, some news headlines stories may share a common subject, such that " Industrial production shrinks globally by 1.1 percent," While different stories are more frequent or one-of-a-kind. Consequently, to locate the significant topics in the last month's stories, we might need to search only for clusters of documents that are firmly related by a common subject. In other cases, a complete Clustering of objects is desired. For example, an application that utilizes Clustering to sort out documents for browsing needs to ensure that all documents can be browsed.
Clustering addresses to discover helpful groups of objects (Clusters), where the objectives of the data analysis characterize utility. Of course, there are various notions of a cluster that demonstrate utility in practice. In order to visually show the differences between these kinds of clusters, we utilize two-dimensional points, as shown in the figure that types of clusters described here are equally valid for different sorts of data.
A cluster is a set of objects where each object is closer or more similar to every other object in the cluster. Sometimes a limit is used to indicate that all the objects in a cluster must be adequately close or similar to each other. The definition of a cluster is satisfied only when the data contains natural clusters that are quite far from one another. The figure illustrates an example of well-separated clusters that comprise of two points in a two-dimensional space. Well-separated clusters do not require to be spherical but can have any shape.

A cluster is a set of objects where each object is closer or more similar to the prototype that characterizes the cluster to the prototype of any other cluster. For data with continuous characteristics, the prototype of a cluster is usually a centroid. It means the average (Mean) of all the points in the cluster when a centroid is not significant. For example, when the data has definite characteristics, the prototype is usually a medoid that is the most representative point of a cluster. For some sorts of data, the model can be viewed as the most central point, and in such examples, we commonly refer to prototype-based clusters as center-based clusters. As anyone might expect, such clusters tend to be spherical. The figure illustrates an example of center-based clusters.

If the data is depicted as a graph, where the nodes are the objects, then a cluster can be described as a connected component. It is a group of objects that are associated with each other, but that has no association with objects that is outside the group. A significant example of graph-based clusters is contiguity-based clusters, where two objects are associated when they are placed at a specified distance from each other. It suggests that every object in a contiguity-based cluster is the same as some other object in the cluster. Figures demonstrate an example of such clusters for two-dimensional points. The meaning of a cluster is useful when clusters are unpredictable or intertwined but can experience difficulty when noise present. It is shown by the two circular clusters in the figure; the little extension of points can join two different clusters.
Other kinds of graph-based clusters are also possible. One such way describes a cluster as a clique. Clique is a set of nodes in a graph that is completely associated with each other. Particularly, we add connections between the objects according to their distance from one another. A cluster is generated when a set of objects forms a clique. It is like prototype-based clusters, and such clusters tend to be spherical.

A cluster is a compressed domain of objects that are surrounded by a region of low density. The two spherical clusters are not merged, as in the figure, because the bridge between them fades into the noise. Similarly, the curve that is present in the Figure disappears into the noise and does not form a cluster in Figure. It also disappears into the noise and does not form a cluster shown in the figure. A density-based definition of a cluster is usually occupied when the clusters are irregularly and intertwined, and when noise and outliers exist. The other hand contiguity-based definition of a cluster would not work properly for the data of Figure. Since the noise would tend to form a network between clusters.


We can describe a cluster as a set of objects that offer some property. The object in a center-based cluster shares the property that they are all closest to the similar centroid or medoid. However, the shared-property approach additionally incorporates new types of the cluster. Consider the cluster given in the figure. A triangular area (cluster) is next to a rectangular one, and there are two intertwined circles (clusters). In both cases, a Clustering algorithm would require a specific concept of a cluster to recognize these clusters effectively. The way of discovering such clusters is called conceptual Clustering.
When it comes to choosing the right tool for clustering, there are a couple of things to consider.
Clustering is a powerful tool for data analysis that can help organizations make better decisions based on their data. There are several types of clustering methods, each with its own strengths and limitations.
By understanding the different types of clustering methods and their applications, you can choose the most appropriate method for your data analysis needs.
There is no one-size-fits-all answer to this question as the best clustering method depends on the type of data you have and the problem you are trying to solve. Some clustering methods work well for low-dimensional data, while others work better for high-dimensional data. It is essential to evaluate different clustering methods and choose the one that works best for your specific problem.
There are several types of cluster analysis, including partitioning, hierarchical, density-based, and model-based clustering. Partitioning clustering algorithms, such as K-means, partition the data into K clusters. Hierarchical clustering algorithms, such as agglomerative and divisive clustering, create a hierarchy of clusters. Density-based clustering algorithms, such as DBSCAN, group together data points that are within a certain distance of each other. Model-based clustering algorithms, such as Gaussian mixture models, assume that the data is generated from a mixture of probability distributions.
Clustering is used in various fields, including marketing, biology, and computer science. Examples of clustering include customer segmentation, image segmentation, and document clustering. In customer segmentation, clustering is used to group customers based on their behavior or preferences. In image segmentation, clustering is used to group pixels with similar properties. In document clustering, clustering is used to group similar documents together.
Fuzzy clustering is a type of soft method in which a data object may belong to more than one group or cluster. Each dataset has a set of membership coefficients, which depend on the degree of membership to be in a cluster. Fuzzy C-means algorithm is the example of this type of clustering; it is sometimes also known as the Fuzzy k-means algorithm.
Fuzzy clustering generalizes the partition-based clustering method by allowing a data object to be a part of more than one cluster. The process uses a weighted centroid based on the spatial probabilities.
The steps include initialization, iteration, and termination, generating clusters optimally analyzed as probabilistic distributions instead of a hard assignment of labels.
The algorithm works by assigning membership values to all the data points linked to each cluster center. It is computed from a distance between the cluster center and the data point. If the membership value of the object is closer to the cluster center, it has a high probability of being in the specific cluster.
At the end iteration, associated values of membership and cluster centers are reorganized. Fuzzy clustering handles the situations where data points are somewhat in between the cluster centers or ambiguous. This is done by choosing the probability rather than distance.
The Clustering algorithms can be divided based on their models that are explained above. There are different types of clustering algorithms published, but only a few are commonly used. The clustering algorithm is based on the kind of data that we are using. Such as, some algorithms need to guess the number of clusters in the given dataset, whereas some are required to find the minimum distance between the observation of the dataset.
Here we are discussing mainly popular Clustering algorithms that are widely used in machine learning:
Clustering algorithms are used in exploring data, anomaly detection, finding outliers, or detecting patterns in the data. Clustering is an unsupervised learning technique like neural network and reinforcement learning. The available data is highly unstructured, heterogeneous, and contains noise. So the choice of algorithm depends upon how the data looks like. A suitable clustering algorithm helps in finding valuable insights for the industry. Let’s explore the different types of clustering in machine learning in detail.
K-Means is a partition-based clustering technique that uses the distance between the Euclidean distances between the points as a criterion for cluster formation. Assuming there are ‘n’ numbers of data objects, K-Means groups them into a predetermined ‘k’ number of clusters.
Each cluster has a cluster center allocated and each of them is placed at farther distances. Every incoming data point gets placed in the cluster with the closest cluster center. This process is repeated until all the data points get assigned to any cluster. Once all the data points are covered the cluster centers or centroids are recalculated.
After having these ‘k’ new centroids, a new grouping is done between the nearest new centroid and the same data set points. Iteratively, there may be a change in the k centroid values and their location this loop continues until the cluster centers do not change or in other words, centroids do not move anymore. The algorithm aims to minimize the objective function

Where
, is the chosen distance between cluster center CJ and data point XI
The correct value of K can be chosen using the Silhouette method and Elbow method. The Silhouette method calculates the distance using the mean intra-cluster distance along with an average of the closest cluster distance for each data point. While the Elbow method uses the sum of squared data points and computes the average distance.
Implementation: K-Means clustering algorithm
Mean shift clustering is a nonparametric, simple, and flexible clustering technique. It is based upon a method to estimate the essential distribution for a given dataset known as kernel density estimation. The basic principle of the algorithm is to assign the data points to the specified clusters recursively by shifting points towards the peak or highest density of data points. It is used in the image segmentation process.

Algorithm:
Ø Step 1 – Creating a cluster for every data point
Ø Step 2 – Computation of the centroids
Ø Step 3 – Update the location of the new centroids
Ø Step 4 – Moving the data points to higher density regions, iteratively.
Ø Step 5 – Terminates when the centroids reach a position where they don’t move further.
The gaussian mixture model (GMM) is a distribution-based clustering technique. It is based on the assumption that the data comprises Gaussian distributions. It is a statistical inference clustering technique. The probability of a point being a part of a cluster is inversely dependent on distance, as the distance from distribution increases, the probability of a point belonging to the cluster decreases. The GM model trains the dataset and assumes a cluster for every object in the dataset. Later, a scatter plot is created with data points with different colors assigned to each cluster.
GMM determines probabilities and allocates them to data points in the ‘K’ number of clusters. Each of which has three parameters: Mean, Covariance and mixing probability. To compute these parameters GMM uses the Expectation Maximization technique.
Source: Alexander Ihler’s YouTube channel
The optimization function initiates the randomly selected Gaussian parameters and checks whether the hypothesis belongs to the chosen cluster. Then, the maximization step updates the parameters to fit the points into the cluster. The algorithm aims at raising the likelihood of the data sample associated with the cluster distribution which states that the cluster distributions have high peaks (closely connected cluster data) and the mixture model captures the dominant pattern data objects by component distribution).
DBSCAN – Density-Based Spatial Clustering of Applications with Noise identifies discrete groups in data. The algorithm aims to cluster the data as contiguous regions having high point density. Each cluster is separated from the others by points of low density. In simpler words, the cluster covers the data points that fit the density criteria which is the minimum number of data objects in a given radius.
Terms used in DBSCAN:
For implementing DBSCAN, we first begin with defining two important parameters – a radius parameter eps (ϵ) and a minimum number of points within the radius (m).


Steps:
Balanced Iterative Reducing and Clustering using Hierarchies, or BIRCH is a clustering technique used for very large datasets. A fast algorithm that scans the entire dataset in a single pass. It is dedicated to solving the issues of large dataset clustering by focusing on densely occupied spaces and creating a precise summary.
BIRCH fits in with any provided amount of memory and minimizes the I/O complexity. The algorithm only works to process metric attributes, which means the one with no categorical variables or the attribute whose value can be represented by explicit coordinates in a Euclidean space. The main parameters of the algorithm are the CR tree and the threshold.
Steps of BIRCH Algorithm
Step 1- Building the Clustering feature (CF) Tree: Building small and dense regions from the large datasets. Optionally, in phase 2 condensing the CF tree into further small CF.
Step 2 – Global clustering: Applying clustering algorithm to leaf nodes of the CF tree.
Step 3 – Refining the clusters, if required.
Clustering is applied in various fields to prepare the data for various machine learning processes. Some of the applications of clustering are as follows.
1. Market segmentation: Businesses need to segment their market into smaller groups to understand the target audience. Clustering groups the like-minded people considering the neighborhood to generate similar recommendations, and it helps in pattern building and insight development.
2. Retail marketing and sales: Marketing utilizes clustering to understand the customers’ purchase behavior to regulate the supply chain and recommendations. It groups people with similar traits and probability of purchase. It helps in reaching the appropriate customer segments and provides effective promotions
3. Social network analysis: Examining qualitative and quantitative social arrangements using network and Graph Theory. Clustering is required to observe the interaction amongst participants to acquire insights regarding various roles and groupings in the network.
4. Wireless network analysis or Network traffic classification: Clustering groups together characteristics of the network traffic sources. Clusters are formed to classify the traffic types. Having precise information about traffic sources helps to grow the site traffic and plan capacity effectively.
5. Image compression: Clustering helps store the images in a compressed form by reducing the image size without any quality compromise.
6. Data processing and feature weighing: The data can be represented as cluster IDs. This saves storage and simplifies the feature data. The data can be accessed using date, time, and demographics.
7. Regulating streaming services: Identifying viewers having similar behavior and interests. Netflix and other OTT platforms cluster the users based on parameters like genre, minutes watched per day, and total viewing sessions to cluster users in groups like high and low usage. This helps in placing advertisements and relevant recommendations for the users.
8. Tagging suggestions using co-occurrence: understanding the search behavior and giving them tags when searched repeatedly. Taking an input for a data set and maintaining a log each time the keyword was searched and tagged it with a certain word. the Number of times two tags appear together can be clustered using some similarity metric.
9. Life science and Healthcare: Clustering creates plant and animal taxonomies to organize genes with analogous functions. It is also used in detecting cancerous cells using medical image segmentation.
10. Identifying good or bad content: Clustering effectively filters out fake news and detects frauds, spam, or rough content by using the attributes like source, keywords, and content.
You may also like to read: Data Mining Techniques, Concepts, and Its Application
Clustering is an integral part of data mining and machine learning. It segments the datasets into groups with similar characteristics, which can help you make better user behavior predictions. Various clustering algorithms explained in the article help you create the best potential groups of data objects. Infinite opportunities can work upon this solid foundation of clustered data.
Clustering
Data Mining - functions
Data mining deals with the kind of patterns that can be mined. On the basis of the kind of data to be mined, there are two categories of functions involved in Data Mining −
Descriptive Function
The descriptive function deals with the general properties of data in the database. Here is the list of descriptive functions −
Class/Concept Description
Mining of Frequent Patterns
Mining of Associations
Mining of Correlations
Mining of Clusters
Class/Concept Description
Class/Concept refers to the data to be associated with the classes or concepts. For example, in a company, the classes of items for sales include computer and printers, and concepts of customers include big spenders and budget spenders. Such descriptions of a class or a concept are called class/concept descriptions. These descriptions can be derived by the following two ways −
Data Characterization − This refers to summarizing data of class under study. This class under study is called as Target Class.
Data Discrimination − It refers to the mapping or classification of a class with some predefined group or class.
Mining of Frequent Patterns
Frequent patterns are those patterns that occur frequently in transactional data. Here is the list of kind of frequent patterns −
Frequent Item Set − It refers to a set of items that frequently appear together, for example, milk and bread.
Frequent Subsequence − A sequence of patterns that occur frequently such as purchasing a camera is followed by memory card.
Frequent Sub Structure − Substructure refers to different structural forms, such as graphs, trees, or frameworks, which may be combined with item-sets or subsequences.
Mining of Association
Associations are used in retail sales to identify patterns that are frequently purchased together. This process refers to the process of uncovering the relationship among data and determining association rules.
For example, a retailer generates an association rule that shows that 70% of time milk is sold with bread and only 30% of times biscuits are sold with bread.
Mining of Correlations
It is a kind of additional analysis performed to uncover interesting statistical correlations between associated-attribute-value pairs or between two item sets to analyze that if they have positive, negative or no effect on each other.
Mining of Clusters
Cluster refers to a group of similar kind of objects. Cluster analysis refers to forming group of objects that are very similar to each other but are highly different from the objects in other clusters.
Classification and Prediction
Classification is the process of finding a model that describes the data classes or concepts. The purpose is to be able to use this model to predict the class of objects whose class label is unknown. This derived model is based on the analysis of sets of training data. The derived model can be presented in the following forms −
Classification (IF-THEN) Rules
Decision Trees
Mathematical Formulae
Neural Networks
The list of functions involved in these processes are as follows −
Classification − It predicts the class of objects whose class label is unknown. Its objective is to find a derived model that describes and distinguishes data classes or concepts. The Derived Model is based on the analysis set of training data i.e. the data object whose class label is well known.
Prediction − It is used to predict missing or unavailable numerical data values rather than class labels. Regression Analysis is generally used for prediction. Prediction can also be used for identification of distribution trends based on available data.
Outlier Analysis − Outliers may be defined as the data objects that do not comply with the general behavior or model of the data available.
Evolution Analysis − Evolution analysis refers to the description and model regularities or trends for objects whose behavior changes over time.
Data Mining Task Primitives
A data mining task can be specified in the form of a data mining query, which is input to the data mining system. A data mining query is defined in terms of data mining task primitives. These primitives allow the user to interactively communicate with the data mining system during discovery to direct the mining process or examine the findings from different angles or depths. The data mining primitives specify the following,
A data mining query language can be designed to incorporate these primitives, allowing users to interact with data mining systems flexibly. Having a data mining query language provides a foundation on which user-friendly graphical interfaces can be built.
Designing a comprehensive data mining language is challenging because data mining covers a wide spectrum of tasks, from data characterization to evolution analysis. Each task has different requirements. The design of an effective data mining query language requires a deep understanding of the power, limitation, and underlying mechanisms of the various kinds of data mining tasks. This facilitates a data mining system's communication with other information systems and integrates with the overall information processing environment.

List of Data Mining Task Primitives
A data mining query is defined in terms of the following primitives, such as:
1. The set of task-relevant data to be mined
This specifies the portions of the database or the set of data in which the user is interested. This includes the database attributes or data warehouse dimensions of interest (the relevant attributes or dimensions). It includes-
It includes database attributes and data warehouse dimensions where only relevant data is extracted by the following process:
In a relational database, the set of task-relevant data can be collected via a relational query involving operations like selection, projection, join, and aggregation.
The data collection process results in a new data relational called the initial data relation. The initial data relation can be ordered or grouped according to the conditions specified in the query. This data retrieval can be thought of as a subtask of the data mining task.
This initial relation may or may not correspond to physical relation in the database. Since virtual relations are called Views in the field of databases, the set of task-relevant data for data mining is called a minable view.
Task relevant data to be mined specifies the portions of the database or the set of data in which the user is interested.
This portion includes the following
For example, suppose that you are a manager of All Electronics in charge of sales in the United States and Canada. You would like to study the buying trends of customers in Canada. Rather than mining on the entire database. These are referred to as relevant attributes.
It includes the Database or data warehouse name, the Database tables or data warehouse cubes and its Conditions for data selection, the Relevant attributes or dimensions and the Data grouping criteria.
For Example
If a data mining task is to study about association between items frequently purchased at
AllElectronics, the task relevant data can be specified by providing the following
information:
2. The kind of knowledge to be mined
This specifies the data mining functions to be performed, such as characterization, discrimination, association or correlation analysis, classification, prediction, clustering, outlier analysis, or evolution analysis. This specifies the data mining functions to be performed, such as
3. The background knowledge to be used in the discovery process
This knowledge about the domain to be mined is useful for guiding the knowledge discovery process and evaluating the patterns found. Concept hierarchies (a sequence of mappings from a set of low-level concepts to higher-level, more general concepts- n data mining, the concept of a concept hierarchy refers to the organization of data into a tree-like structure, where each level of the hierarchy represents a concept that is more general than the level below it. This hierarchical organization of data allows for more efficient and effective data analysis, as well as the ability to drill down to more specific levels of detail when needed. The concept of hierarchy is used to organize and classify data in a way that makes it more understandable and easier to analyze.) are a popular form of background knowledge, which allows data to be mined at multiple levels of abstraction.
Users can specify background knowledge, or knowledge about the domain to be mined. This knowledge is useful for guiding the knowledge discovery process, and for evaluating the patterns found. User beliefs about relationship in the data.
There are several kinds of background knowledge. Concept hierarchies are a popular form of background knowledge, which allow data to be mined at multiple levels of abstraction.
Example:
An example of a concept hierarchy for the attribute (or dimension) age is shown in the following Figure.

In the above, the root node represents the most general abstraction level, denoted as all.
Concept hierarchy defines a sequence of mappings from low-level concepts to higher-level, more general concepts.
The Four major types of concept hierarchies are
1. schema hierarchies
2. set-grouping hierarchies
3. operation-derived hierarchies
4. rule-based hierarchies
Schema hierarchies
In Schema hierarchy gives the total or partial order among attributes in the database schema. It may formally express existing semantic relationships between attributes. It provides metadata information.
Example: location hierarchy like
street < city < province/state < country
Set-grouping hierarchies
This Organizes the values for a given attribute into groups or sets or range of values. Total or partial order can be defined among the groups. It is used to refine or enrich schemadefined hierarchies. Typically used for small sets of object relationships.
Example:
Set-grouping hierarchy for age {young, middle_aged, senior} which is a proper subset of
all (age)
{20«.29} proper subset young
{40«.59} proper subset middle_aged
{60«.89} proper subset senior
Operation-derived hierarchies
Operation-derived hierarchies are based on operations specified. The operations may include decoding of information-encoded strings, information extraction from complex data objects and data clustering
Example could be URL or email address
Consider
xyz@cs.iitm.in gives login name < dept. < univ. < country
Rule-based hierarchies
It Occurs when either whole or portion of a concept hierarchy is defined as a set of rules and it is evaluated dynamically based on current database data and rule definition
Example:
Following rules are used to categorize items as low_profit, medium_profit and
high_profit_margin. Each defined as,
low_profit_margin(X) <= price(X,P1)^cost(X,P2)^((P1-P2)<50)
medium_profit_margin(X) <= price(X,P1)^cost(X,P2)^((P1- P2)>=50)^((P1-P2)<=250)
high_profit_margin(X) <= price(X,P1)^cost(X,P2)^((P1-P2)>250)
4. The interestingness measures and thresholds for pattern evaluation
Different kinds of knowledge may have different interesting measures. They may be used to guide the mining process or, after discovery, to evaluate the discovered patterns. For example, interesting measures for association rules include support and confidence. Rules whose support and confidence values are below user-specified thresholds are considered uninteresting.
5. The expected representation for visualizing the discovered patterns
This refers to the form in which discovered patterns are to be displayed, which may include rules, tables, cross tabs, charts, graphs, decision trees, cubes, or other visual representations.
Users must be able to specify the forms of presentation to be used for displaying the discovered patterns. Some representation forms may be better suited than others for particular kinds of knowledge.
For example, generalized relations and their corresponding cross tabs or pie/bar charts are good for presenting characteristic descriptions, whereas decision trees are common for classification.
Data mining query languages
spectrum of tasks and each task has different requirement.
Data mining query languages
Based on the primitives discussed earlier.
DMQL
[ ] represents 0 or one occurrence
{ } represents 0 or more occurrences
Words in sans serif represent keywords
DMQL-Syntax for task-relevant data specification
Advantages of Data Mining Task Primitives
The use of data mining task primitives has several advantages, including:
What is Data Mining?
Data mining is the process of extracting knowledge or insights from large amounts of data using various statistical and computational techniques. The data can be structured, semi-structured or unstructured, and can be stored in various forms such as databases, data warehouses, and data lakes.
The primary goal of data mining is to discover hidden patterns and relationships in the data that can be used to make informed decisions or predictions. This involves exploring the data using various techniques such as clustering, classification, regression analysis, association rule mining, and anomaly detection.
Data mining is the process of extracting useful information from an accumulation of data, often from a data warehouse or collection of linked data sets. Data mining tools include powerful statistical, mathematical, and analytics capabilities whose primary purpose is to sift through large sets of data to identify trends, patterns, and relationships to support informed decision-making and planning.
Data mining has a wide range of applications across various industries, including marketing, finance, healthcare, and telecommunications. For example, in marketing, data mining can be used to identify customer segments and target marketing campaigns, while in healthcare, it can be used to identify risk factors for diseases and develop personalized treatment plans.
However, data mining also raises ethical and privacy concerns, particularly when it involves personal or sensitive data. It’s important to ensure that data mining is conducted ethically and with appropriate safeguards in place to protect the privacy of individuals and prevent misuse of their data.
Often associated with marketing department inquiries, data mining is seen by many executives as a way to help them better understand demand and to see the effect that changes in products, pricing, or promotion have on sales. But data mining has considerable benefit for other business areas as well. Engineers and designers can analyse the effectiveness of product changes and look for possible causes of product success or failure related to how, when, and where products are used. Service and repair operations can better plan parts inventory and staffing. Professional service organisations can use data mining to identify new opportunities from changing economic trends and demographic shifts.
Data mining becomes more useful and valuable with bigger data sets and with more user experience. Logically, the more data, the more insights and intelligence should be buried there. Also, as users get more familiar with the tools and better understand the database, the more creative they can be with their explorations and analyses.
Many terms, including information mining from data, information harvesting, information analysis, and data dredging, have meanings that are similar to or slightly distinct from those of data mining. Knowledge Discovery from Data, often known as KDD, is another commonly used phrase that data mining uses as a synonym. Others see data mining as just a crucial stage in the knowledge discovery process when intelligent techniques are used to extract patterns in data. Now that we have explored what exactly data mining is let us explore its areas of usage.
It is also important to note that data mining is a subset of data science, and it is closely related to other fields such as machine learning and artificial intelligence.
Why use data mining?
The primary benefit of data mining is its power to identify patterns and relationships in large volumes of data from multiple sources. With more and more data available – from sources as varied as social media, remote sensors, and increasingly detailed reports of product movement and market activity – data mining offers the tools to fully exploit Big Data and turn it into actionable intelligence. What’s more, it can act as a mechanism for “thinking outside the box.”
The data mining process can detect surprising and intriguing relationships and patterns in seemingly unrelated bits of information. Because information tends to be compartmentalized, it has historically been difficult or impossible to analyse as a whole. However, there may be a relationship between external factors – perhaps demographic or economic factors – and the performance of a company’s products. And while executives regularly look at sales numbers by territory, product line, distribution channel, and region, they often lack external context for this information. Their analysis points out “what happened” but does little to uncover the “why it happened this way.” Data mining can fill this gap.
Data mining can look for correlations with external factors; while correlation does not always indicate causation, these trends can be valuable indicators to guide product, channel, and production decisions. The same analysis benefits other parts of the business from product design to operational efficiency and service delivery.
History of data mining
People have been collecting and analysing data for thousands of years and, in many ways, the process has remained the same: identify the information needed, find quality data sources, collect and combine the data, use the most effective tools available to analyse the data, and capitalise on what you’ve learned. As computing and data-based systems have grown and advanced, so have the tools for managing and analysing data. The real inflection point came in the 1960s with the development of relational database technology and user-orientated natural language query tools like Structured Query Language (SQL). No longer was data only available through custom coded programmes. With this breakthrough, business users could interactively explore their data and tease out the hidden gems of intelligence buried inside.
Data mining has traditionally been a speciality skill set within data science. Every new generation of analytical tools, however, starts out requiring advanced technical skills but quickly evolves to become accessible to users. Interactivity – the ability to let the data talk to you – is the key advancement. Ask a question; see the answer. Based on what you learn, ask another question. This kind of unstructured roaming through the data takes the user beyond the confines of the application-specific database design and allows for the discovery of relationships that cross functional and organisational boundaries.
Data mining is a key component of business intelligence. Data mining tools are built into executive dashboards, harvesting insight from Big Data, including data from social media, Internet of Things (IoT) sensor feeds, location-aware devices, unstructured text, video, and more. Modern data mining relies on the cloud and virtual computing, as well in-memory databases, to manage data from many sources cost-effectively and to scale on demand.
How does data mining work?
Data mining can be seen as a subset of data analytics that specifically focuses on extracting hidden patterns and knowledge from data. Historically, a data scientist was required to build, refine, and deploy models. However, with the rise of AutoML tools, data analysts can now perform these tasks if the model is not too complex.
The data mining process may vary depending on your specific project and the techniques employed, but it typically involves the 10 key steps described below.

1. Define Problem. Clearly define the objectives and goals of your data mining project. Determine what you want to achieve and how mining data can help in solving the problem or answering specific questions.
2. Collect Data. Gather relevant data from various sources, including databases, files, APIs, or online platforms. Ensure that the collected data is accurate, complete, and representative of the problem domain. Modern analytics and BI tools often have data integration capabilities. Otherwise, you’ll need someone with expertise in data management to clean, prepare, and integrate the data.
3. Prep Data. Clean and preprocess your collected data to ensure its quality and suitability for analysis. This step involves tasks such as removing duplicate or irrelevant records, handling missing values, correcting inconsistencies, and transforming the data into a suitable format.
4. Explore Data. Explore and understand your data through descriptive statistics, visualization techniques, and exploratory data analysis. This step helps in identifying patterns, trends, and outliers in the dataset and gaining insights into the underlying data characteristics.
5. Select predictors. This step, also called feature selection/engineering, involves identifying the relevant features (variables) in the dataset that are most informative for the task. This may involve eliminating irrelevant or redundant features and creating new features that better represent the problem domain.
6. Select Model. Choose an appropriate model or algorithm based on the nature of the problem, the available data, and the desired outcome. Common techniques include decision trees, regression, clustering, classification, association rule mining, and neural networks. If you need to understand the relationship between the input features and the output prediction (explainable AI), you may want a simpler model like linear regression. If you need a highly accurate prediction and explainability is less important, a more complex model such as a deep neural network may be better.
7. Train Model. Train your selected model using the prepared dataset. This involves feeding the model with the input data and adjusting its parameters or weights to learn from the patterns and relationships present in the data.
8. Evaluate Model. Assess the performance and effectiveness of your trained model using a validation set or cross-validation. This step helps in determining the model's accuracy, predictive power, or clustering quality and whether it meets the desired objectives. You may need to adjust the hyperparameters to prevent overfitting and improve the performance of your model.
9. Deploy Model. Deploy your trained model into a real-world environment where it can be used to make predictions, classify new data instances, or generate insights. This may involve integrating the model into existing systems or creating a user-friendly interface for interacting with the model.
10. Monitor & Maintain Model. Continuously monitor your model's performance and ensure its accuracy and relevance over time. Update the model as new data becomes available, and refine the data mining process based on feedback and changing requirements.
Flexibility and iterative approaches are often required to refine and improve the results throughout the process.
There are about as many approaches to data mining as there are data miners. The approach depends on the kind of questions being asked and the contents and organisation of the database or data sets providing the raw material for the search and analysis. That said, there are some organisational and preparatory steps that should be completed to prepare the data, the tools, and the users:
Where is Data Mining (DM) Used?
Numerous sectors, including healthcare, retail, banking, government, and manufacturing, use Data Mining extensively.
For instance, if a business wants to recognize trends or patterns among the customers who purchase particular goods, it can use data-gathering techniques to examine past purchases and create models that anticipate which customers will want to purchase merchandise based on their features or behavior. Data mining, therefore, aids businesses in creating more effective sales techniques in the retail industry.
These tools can also be applied to:
Applications of Data Mining
Additionally, data mining methods are becoming more popular in practically every industry, including banking, logistics, finance, and science. Data mining is also used in intelligence and law enforcement:
Data mining is employed in finance to:
In the field of education, Data Mining aids in creating unique programs based on the following:
We will now be looking at the various stages of the data mining process.
Stages of The Data Mining Process (from first to end all steps so incorporate the mining process also)
There are essentially three main stages of the data mining process:
1. Preparatory Stage
Setting Business Goals
Finding out the project's ultimate purpose and how it will help the organization is the first stage. The objective can be to categorize the basis of consumers on their tastes or behavior, better understand market trends, or forecast purchasing behaviors.
Data Cleaning and Extracting(means prepare data-preprocessing)
The next step is to gather pertinent data from various repositories, including CRMs, databases, websites, social media, etc. Data from all of these sources will need to be combined and then formatted so that it can be used for research (analysis).
Once you've obtained the necessary data, you must pre-process it to make it suitable for analysis. Data organization and cleaning are required for this.
2. Data Mining Proper
Data Exploration (examine data)
It is crucial to comprehend the data before beginning to analyze it. Finding patterns or connections in data is what data exploration is all about.
Forming Hypothesis
It is now time to look for undiscovered clusters, patterns, and trends in the data. Algorithms for classification, forecasting, and grouping are used in this phase. Suitable methods, such as pass, bootstrapping, and loss matrix analysis, are used to evaluate each hypothesis. The most useful theories are gathered and then disclosed to the general audience.
3. Post-Processing: Presentation (after model deployement)
The results must be presented in a way that is concise, organized, and simple to comprehend in order for them to be translated into insightful business information. The key findings, such as patterns, patterns, or connections that will enable data-driven decision-making, can be highlighted by visualizing it as a paper, diagram, or infographic.
Top 10 Data Mining Techniques
Types of Data Mining
Each of the following data mining techniques serves several different business problems and provides a different insight into each of them. However, understanding the type of business problem you need to solve will also help in knowing which technique will be best to use, which will yield the best results. The Data Mining types can be divided into two basic parts that are as follows:
1. Predictive Data Mining
As the name signifies, Predictive Data-Mining analysis works on the data that may help to know what may happen later (or in the future) in business. Predictive Data-Mining can also be further divided into four types that are listed below:
2. Descriptive Data Mining
The main goal of the Descriptive Data Mining tasks is to summarize or turn given data into relevant information. The Descriptive Data-Mining Tasks can also be further divided into four types that are as follows:
Here, we will discuss each of the data mining's types in detail. Below are several different data mining techniques that can help you find optimal outcomes as the results.
1. CLASSIFICATION ANALYSIS
This type of data mining technique is generally used in fetching or retrieving important and relevant information about the data & metadata. It is also even used to categories the different types of data format into different classes. If you focus on this article until it ends, you may definitely find out that Classification and clustering are similar data mining types. As clustering also categorizes or classify the data segments into the different data records known as the classes. However, unlike clustering, the data analyst would have the knowledge of different classes or clusters. Therefore in the classification analysis, you have to apply or implement the algorithms to decide in which way the new data should be categorized or classified. A classic example of classification analysis would be Outlook email. In Outlook, they use certain algorithms to characterize an email is legitimate or spam.
This technique is usually very helpful for retailers who can use it to study the buying habits of their different customers. Retailers can also study the past sales data and then lookout (or search ) for products that customers usually buy together. After which, they can put those products nearby of each other in their retail stores to help customers save their time and as well as to increase their sales.
2. REGRESSION ANALYSIS
In statistical terms, regression analysis is a process usually used to identify and analyze the relationship among variables. It means one variable is dependent on another, but it is not vice versa. It is generally used for prediction and forecasting purposes. It can also help you understand the characteristic value of the dependent variable changes if any of the independent variables is varied.
3. Time Serious Analysis
A time series is a sequence of data points that are usually recorded at specific time intervals of points. Usually, they are - most often in regular time intervals (seconds, hours, days, months etc.). Almost every organization generates a high volume of data every day, such as sales figures, revenue, traffic, or operating cost. Time series data mining can help in generating valuable information for long-term business decisions, yet they are underutilized in most organizations.
4. Prediction Analysis
This technique is generally used to predict the relationship that exists between both the independent and dependent variables as well as the independent variables alone. It can also use to predict profit that can be achieved in future depending on the sale. Let us imagine that profit and sale are dependent and independent variables, respectively. Now, on the basis of what the past sales data says, we can make a profit prediction of the future using a regression curve.
5. Clustering Analysis
In Data Mining, this technique is used to create meaningful object clusters that contain the same characteristics. Usually, most people get confused with Classification, but they won't have any issues if they properly understand how both these techniques actually work. Unlike Classification that collects the objects into predefined classes, clustering stores objects in classes that are defined by it. To understand it in more detail, you can consider the following given example:
Example
Suppose you are in a library that is full of books on different topics. Now the real challenge for you is to organize those books so that readers don't face any problem finding out books on any particular topic. So here, we can use clustering to keep books with similarities in one particular shelf and then give those shelves a meaningful name or class. Therefore, whenever a reader looking for books on a particular topic can go straight to that shelf. Hence he won't be required to roam the entire library to find the book he wants to read.
6. SUMMARIZATION ANALYSIS
The Summarization analysis is used to store a group (or a set ) of data in a more compact way and an easier-to-understand form. We can easily understand it with the help of an example:
Example
You might have used Summarization to create graphs or calculate averages from a given set (or group) of data. This is one of the most familiar and accessible forms of data mining.
7. ASSOCIATION RULE LEARNING
In general, it can be considered a method that can help us identify some interesting relations (dependency modeling) between different variables in large databases. This technique can also help us to unpack some hidden patterns in the data, which can be used to identify the variables within the data. It also helps in detecting the concurrence of different variables that appear very frequently in the dataset. Association rules are generally used for examining and forecasting the behavior of the customer. It is also highly recommended in the retail industry analysis. This technique is also used to determine shopping basket data analysis, catalogue design, product clustering, and store layout. In IT, programmers also uses the association rules to create programs capable of machine learning. Or in short, we can say that this data mining technique helps to find the association between two or more Items. It discovers a hidden pattern in the data set.
8. Sequence Discovery Analysis
The primary goal of sequence discovery analysis is to discover interesting patterns in data on the basis of some subjective or objective measure of how interesting it is. Usually, this task involves discovering frequent sequential patterns with respect to a frequency support measure. Some people may often confuse it with time series as both the Sequence discovery analysis and Time series analysis contains the adjacent observation that are order dependent. However, if the people see both of them in a little more depth, their confusion can be easily avoided as the Time series analysis technique contains numerical data, whereas the Sequence discovery analysis contains discrete values or data.
1) Pattern Tracking
Pattern tracking is one of the fundamental data mining techniques. It entails recognizing and monitoring trends in sets of data to make intelligent analyses regarding business outcomes. For a business, this process could relate to anything from identifying top-performing demographics or understanding seasonal variations in the customer’s buying behavior.
For instance, the pattern in sales data may show that a certain product is more popular amongst specific demographics or a decrease in total sales volume after the holiday season. The company can then use this information to target specific markets and optimize the supply chain.
2) Association
Like pattern tracking, the association technique involves looking for certain occurrences with connected attributes. The idea is to look for linked variables depending on specific attributes or events. Association rules can be particularly useful for studying consumer behavior.
For example, an online store might learn that customers who purchase a certain product will likely buy a complementary item. Using this insight, they can provide better recommendations to maximize the sales revenue. This technique can also be used in catalog design, product clustering, layout design, etc.

3) Classification
It’s a useful data mining technique used to derive relevant data and metadata based on a defined attribute, for example, type of data sources, data mining functionalities, and more. Basically, it’s the process of dividing large datasets into target categories. This categorization is also determined by the data framework, for example, relational database, object-oriented database, etc. It comes in the scope of data preparation.
Suppose your company wants to forecast the change in revenue for customers given a loyalty membership. You can create a category that contains customers’ demographic data with a loyalty membership to design a binary classification model to predict an increase or decrease in spending.
4) Outlier Detection
There are instances when the data pattern doesn’t provide a clear understanding of the data. In such situations, the outlier detection technique comes handy. It involves identifying anomalies or “outliers” in your dataset to understand specific causations or derive more accurate predictions.
Here’s an example. Suppose your sales always range between $7,000 to $10,000 per week. But one week, the sales revenue crosses $40,000, without any obvious seasonal factors at play. You’ll want to understand the reason behind the surge in sales so you can replicate it and gain a better understanding of your customer base.
5) Clustering
Like classification, clustering is a data mining technique that involves grouping data based on similarities. It helps in knowledge discovery, anomaly detection, and gaining insights into the internal structure of the data.
For instance, you might cluster audiences from different regions into packets based on their age group, gender, and disposable income, so you can tailor your marketing campaign to maximize your reach.
The results of cluster data analysis are typically shown using graphs to help users visualize data distribution and identify trends in their datasets.
6) Sequential Patterns
Sequential data refers to a type of data where the order of observations is crucial. Each data point is part of a sequence, and the sequence’s integrity is essential for analysis. This type of data is not necessarily time-based; it can represent sequences such as text, DNA strands, or user actions1.
Types of Sequential Data
Importance of Sequential Data
Analyzing sequential data helps uncover underlying patterns, dependencies, and structures in various fields. It is vital for tasks such as natural language processing, bioinformatics, and user behavior analysis, enabling better predictions, classifications, and understanding of sequential patterns1.
As the name suggests, this is a mining technique that focuses on discovering patterns or a series of events taking place in a sequence. It’s extensively used in transactional data mining but has numerous applications. For instance, it can help companies recommend relevant items to customers to maximize sales.
An example would be a sequential trend identified at an electronics store where customers who purchase an iPhone are likely to purchase a MacBook within six months. The retailer can use this intelligence to create targeted marketing campaigns to upsell to iPhone buyers. For example, bundle offer of Apple products to maximize turnover.

7) Decision tree
A decision tree is a data mining technique in machine learning (ML) that focuses on input and output modeling relationships using if/then rules. With this approach, you can learn how the data inputs influence outputs. The trees are typically designed in a top-down, flowchart-like structure.
For example:
This decision tree is a simplified example. A predictive analytics model with several decision tree models facilitates more complex data analytics.
Decision trees are mainly used for classification and regression models.
8) Regression Analysis
It’s one of the most popular data mining techniques in machine learning that utilizes the linear relationship between variables. It helps you predict the future value of variables. The technique has numerous applications in financial forecasting, resource planning, strategic decision-making, and more.
For example, you can use regression analysis to understand the correlation between education, income, and spending habits. The complexity of the prediction increases as you add more variables. The common techniques include standard multiple, stepwise, and hierarchical regression.
9) Long-term Memory Processing
Long-term memory processing is a data mining technique in machine learning used to analyze data over long periods. It allows you to identify time-based data patterns, such as climate data, more effectively. It’s intended to scale data in the system memory and utilize additional information in the analysis.
For instance, you can design a predictive model to identify fraudulent transactions by assigning probabilities. You can use this model for existing transactions and then, after some time, update the model with the data derived from new transactions, resulting in improved decision-making.
10) Neural Networks
A neural network is also one of the popular data mining techniques in machine learning models used with Artificial Intelligence (AI). Like neurons in the brain, it seeks to identify relationships in data. Neural networks have different layers working together to produce data analytics results with great accuracy.
These models look for patterns in a large amount of data. While they can be highly complex as a result, the output generated Can provide extremely valuable insights to organizations.
Data Mining Analytics
At the heart of data mining analytics lie statistical techniques, forming the foundation for various analytical models. These models produce numerical outputs tailored to specific business objectives. From neural networks to machine learning, statistical concepts drive these techniques, contributing to the dynamic field of artificial intelligence.
Data Visualizations
Data visualizations play a crucial role in data mining, offering users insights based on sensory perceptions. Today’s dynamic visualizations, characterized by vibrant colors, are adept at handling real-time streaming data. Dashboards, built upon different metrics and visualizations, become powerful tools to uncover data mining insights, moving beyond numerical outputs to visually highlight trends and patterns.
Deep Learning
Neural networks, a subset of machine learning, draw inspiration from the human brain’s neuron structure. While potent for data mining, their complexity necessitates caution. Despite the intricacy, neural networks stand out as accurate models in contemporary machine learning applications, particularly in AI and deep learning scenarios.
Data Warehousing
Data warehousing, a pivotal component of data mining, has evolved beyond traditional relational databases. Modern approaches, including cloud data warehouses and those accommodating semi-structured and unstructured data in platforms like Hadoop, enable comprehensive, real-time data analysis, extending beyond historical data usage.
Analyzing Insights
Long-term memory processing involves the analysis of data over extended periods. Utilizing historical data, organizations can identify subtle patterns that might evade detection otherwise. This method proves particularly useful for tasks such as analyzing attrition trends over several years, providing insights that contribute to reducing churn in sectors like finance.
ML and AI
Machine learning and artificial intelligence represent cutting-edge advancements in data mining. Advanced forms like deep learning excel in accurate predictions at scale, making them invaluable for AI deployments such as computer vision, speech recognition, and sophisticated text analytics using natural language processing. These techniques shine in extracting value from semi-structured and unstructured data.
Different Types of Data Mining Techniques
1. Classification
Data are categorized to separate them into predefined groups or classes. Based on the values of a number of attributes, this method of data mining identifies the class to which a document belongs. Sorting data into predetermined classes is the aim.
Predicting a variable that can have one of two or more different values (for example, spam/not spam; good or neutral/negative evaluation) given one or even more input factors called predictors is the most typical application of classification.
2. Clustering
The next data mining technique is clustering. Similar entries inside a database are grouped together using the clustering approach to form clusters. The clustering first identifies these groups inside the dataset and afterward classifies factors based on their properties, in contrast to classification, which places variables into established categories.
For instance, you can group clients based on sales data, such as those who consistently purchase certain drinks or pet food and have consistent taste preferences. You may easily target these clusters with specialized adverts once you've established them.
Clustering has several uses, including the following:
3. Association Rule Learning
Finding if-then patterns between two or more independent variables is done through association rule learning. The relationship between purchasing bread and butter is the most basic illustration. Butter is frequently purchased along with bread, and vice versa. Because of this, you can find these two products side by side at a grocery shop.
The connection might not be so direct, though. For instance, Walmart found in 2004 that Strawberry Pop-Tart sales peaked just before the hurricane. Along with stocking up on necessities like batteries, many also bought these well-liked treats.
In hindsight, the psychological motive is rather clear: having your favorite meal on hand during emergencies gives you a sense of security, and tarts with a long shelf life are the ideal choice. But data mining methods had to be used in order to identify this association.
4. Regression
The next data mining technique is Regression. A link between variables is established using regression. Its objective is to identify the appropriate function that best captures the relationship. Linear regression analysis is the term used when a linear function (y = axe + b) is applied.
Methods like multiple linear regression, quadratic regression, etc., can be used to account for additional kinds of relationships. Planning and modeling are the two most prevalent applications. One illustration is estimating a customer's age based on past purchases. We may also forecast costs based on factors like consumer demand; for instance, if demand for vehicles in the US increases, prices on the secondary market would rise.
5. Anomaly Detection
A data mining technique called anomaly detection is used to find outliers (values that deviate from the norm). For instance, it can identify unexpected sales at a store location during a specific week in e-commerce information. It can be used, among other things, to find credit or debit fraud and spot network attacks or disruptions.
6. Sequential Pattern Mining
A data mining technique known as sequential pattern mining finds significant connections between events. We can discuss a dependency between events when we can pinpoint a time-ordered sequence that occurs with a particular frequency.
Let's imagine we wish to look into how a drug or a specific therapeutic approach affects cancer patients' life expectancy. By including a temporal component in the study, sequential pattern mining makes it possible for you to do that.
This method can be used, among other things, in medicine to determine how to administer a patient's medicines and in security to foresee potential systemic attacks.
Sequential pattern mining has several uses, such as:
7. Artificial Neural Network Classifier
A process model supported by biological neurons could be an artificial neural network (ANN), also known as a "Neural Network" (NN). It is made up of a networked group of synthetic neurons. A neural network is a collection of connected input/output units with weights assigned to each connection.
In order to be able to anticipate the class label of the input samples correctly, the network accumulates information during the knowledge phase by modifying the weights. Due to the links between units, neural network learning is also known as connectionist learning.
Neural networks require lengthy training periods, making them more suitable for applications where it is possible. They need a variety of parameters, like the network topology or "structure," which are often best determined empirically.
Since it is challenging for humans to understand the symbolic significance of the acquired weights, neural networks have come under fire for their poor interpretability. First, these characteristics reduced the appeal of neural networks for data mining.
However, neural networks' strengths include their high level of noise tolerance and their capacity to classify patterns for which they have not yet been taught. Additionally, a number of novel methods have been created to extract rules from trained neural networks. These problems affect how effective neural networks are at classifying data in data mining.
An artificial neural network is a machine that modifies its structure in response to information that passes through it during a learning phase. The learning-by-example principle underlies the ANN. Perceptron and multilayer perceptron are two of the most traditional neural network architectures.
8. Outlier Analysis
Data objects that do not adhere to the overall behavior or model of the data may be found in a database. These informational items are outliers. OUTLIER MINING is the process of looking into OUTLIER data.
When employing distance measurements, objects with a tiny percentage of "near" neighbors in space are regarded as outliers. Statistical tests that assume a distribution and probability model for the data can also be used to identify outliers.
Deviation-based strategies identify exceptions/outliers by examining variances in the primary features of items in a collection rather than using factual or distance metrics.
9. Prediction
The next data mining technique is Prediction. Data classification and data prediction both involve two steps. Despite the fact that we do not use the term "Class label attribute" for prediction because the attribute whose values are being forecasted is consistently valued (ordered) rather than category (discrete-esteemed and unordered).
Simply calling the attribute "the expected attribute" will do. Prediction can be thought of as the creation and use of a model to determine the class of an unlabeled item or the value or ranges of a particular attribute that an object is likely to possess.
10. Genetic Algorithms
The majority of evolutionary algorithms are genetic algorithms, which are adaptive heuristic algorithms. Natural selection and genetics are the foundations of genetic algorithms. These are clever uses of random search that are supported by historical data to focus the search on areas with superior performance in the solution space. They are frequently employed to produce excellent answers to optimization and search-related issues.
Natural selection is simulated by genetic algorithms, which means that only those species that can adapt to changes in their environment will be able to survive, procreate, and pass on to the next generation.
Types and Part of Data Mining architecture
Data Mining refers to the detection and extraction of new patterns from the already collected data. Data mining is the amalgamation of the field of statistics and computer science aiming to discover patterns in incredibly large datasets and then transform them into a comprehensible structure for later use.
The architecture of Data Mining:

Basic Working:
A detailed description of parts of data mining architecture is shown:
Types of Data Mining architecture:
Advantages of Data Mining:
Disadvantages of Data Mining:
Data mining challenges
What are the three types of Data Mining?
Answer:
The three types of data mining are:
Q.3 What are the four stages of Data Mining?
Answer:
The four Stages of Data Mining Include:-
Q.4 What are Data Mining Tools?
Answer:
The Most Popular Data Mining tools that are used frequently nowadays are R, Python, KNIME, RapidMiner, SAS, IBM SPSS Modeler and Weka.
KDD Process in Data Mining
In the context of computer science, “Data Mining” can be referred to as knowledge mining from data, knowledge extraction, data/pattern analysis, data archaeology, and data dredging. Data Mining also known as Knowledge Discovery in Databases, refers to the nontrivial extraction of implicit, previously unknown and potentially useful information from data stored in databases.
The need of data mining is to extract useful information from large datasets and use it to make predictions or better decision-making. Nowadays, data mining is used in almost all places where a large amount of data is stored and processed.
For examples: Banking sector, Market Basket Analysis, Network Intrusion Detection.
KDD Process
KDD (Knowledge Discovery in Databases) is a process that involves the extraction of useful, previously unknown, and potentially valuable information from large datasets. The KDD process is an iterative process and it requires multiple iterations of the above steps to extract accurate knowledge from the data.The following steps are included in KDD process:
Data Cleaning
Data cleaning is defined as removal of noisy and irrelevant data from collection.
Data Integration
Data integration is defined as heterogeneous data from multiple sources combined in a common source(DataWarehouse). Data integration using Data Migration tools, Data Synchronization tools and ETL(Extract-Load-Transformation) process.
Data Selection
Data selection is defined as the process where data relevant to the analysis is decided and retrieved from the data collection. For this we can use Neural network, Decision Trees, Naive bayes, Clustering, and Regression methods.
Data Transformation
Data Transformation is defined as the process of transforming data into appropriate form required by mining procedure. Data Transformation is a two step process:
Data Mining
Data mining is defined as techniques that are applied to extract patterns potentially useful. It transforms task relevant data into patterns, and decides purpose of model using classification or characterization.
Pattern Evaluation
Pattern Evaluation is defined as identifying strictly increasing patterns representing knowledge based on given measures. It find interestingness score of each pattern, and uses summarization and Visualization to make data understandable by user.
Knowledge Representation
This involves presenting the results in a way that is meaningful and can be used to make decisions.

Note: KDD is an iterative process where evaluation measures can be enhanced, mining can be refined, new data can be integrated and transformed in order to get different and more appropriate results.Preprocessing of databases consists of Data cleaning and Data Integration.
Advantages of KDD
Disadvantages of KDD
Difference between KDD and Data Mining
|
Parameter |
KDD |
Data Mining |
|
Definition |
KDD refers to a process of identifying valid, novel, potentially useful, and ultimately understandable patterns and relationships in data. |
Data Mining refers to a process of extracting useful and valuable information or patterns from large data sets. |
|
Objective |
To find useful knowledge from data. |
To extract useful information from data. |
|
Techniques Used |
Data cleaning, data integration, data selection, data transformation, data mining, pattern evaluation, and knowledge representation and visualization. |
Association rules, classification, clustering, regression, decision trees, neural networks, and dimensionality reduction. |
|
Output |
Structured information, such as rules and models, that can be used to make decisions or predictions. |
Patterns, associations, or insights that can be used to improve decision-making or understanding. |
|
Focus |
Focus is on the discovery of useful knowledge, rather than simply finding patterns in data. |
Data mining focus is on the discovery of patterns or relationships in data. |
|
Role of domain expertise |
Domain expertise is important in KDD, as it helps in defining the goals of the process, choosing appropriate data, and interpreting the results. |
Domain expertise is less critical in data mining, as the algorithms are designed to identify patterns without relying on prior knowledge. |
Data Preprocessing in Data Science
Overview
Data Preprocessing can be defined as a process of converting raw data into a format that is understandable and usable for further analysis. It is an important step in the Data Preparation stage. It ensures that the outcome of the analysis is accurate, complete, and consistent.
Understanding Data
The main objective of Data Understanding is to gather general insights about the input dataset that will help to perform further steps to preprocess data. Let’s review two of the most common ways to understand input datasets
Data Types
Data Type can be defined as labeling the values a feature can hold. The data type will also determine what kinds of relational, mathematical, or logical operations can be performed on it. A few of the most common data types include Integer, Floating, Character, String, Boolean, Array, Date, Time, etc.
Data Summary
Data Summary can be defined as generating descriptive or summary statistics for the features in a given dataset. For example, for a numeric column, it will compute mean, max, min, std, etc. For a categorical variable, it will compute the count of unique labels, labels with the highest frequency, etc.
Data Preprocessing in Data Mining
Data preprocessing is an important step in the data mining process. It refers to the cleaning, transforming, and integrating of data in order to make it ready for analysis. The goal of data preprocessing is to improve the quality of the data and to make it more suitable for the specific data mining task.
Businesses use digital data for various purposes, such as maintaining archives or records, monitoring transactions, predicting market or business trends, and performing other routine business activities. Preprocessing raw data before making important business decisions can help businesses increase their productivity and profits.
What is data preprocessing?
Real-world datasets are generally messy, raw, incomplete, inconsistent, and unusable. It can contain manual entry errors, missing values, inconsistent schema, etc. Data Preprocessing is the process of converting raw data into a format that is understandable and usable. It is a crucial step in any Data Science project to carry out an efficient and accurate analysis. It ensures that data quality is consistent before applying any Machine Learning or Data Mining techniques.
Data preprocessing is converting raw data into legible and defined sets that allow businesses to conduct data mining, analyze the data, and process it for business activities. It's important for businesses to preprocess their data correctly, as they use various forms of input to collect raw data, which can affect its quality. Preprocessing data is an important step, as raw data can be inconsistent or incomplete in its formatting. Effectively preprocessing raw data can increase its accuracy, which can increase the quality of projects and improve its reliability.Related: What Is Parallel Processing? (With Types and FAQs)
Importance of data preprocessing
Preprocessing data is an important step for data analysis. The following are some benefits of preprocessing data:
How is Data Preprocessing Used?//CAN INCLUDE IN SIGNIFICANCE/ADVANTAGES
Ensuring High-Quality Data
Refining Model Accuracy and Performance
Feature engineering, an essential facet of model development, is greatly facilitated by preprocessing. It enables innovative features from existing data, refining model performance.
Accelerate the Learning Process and Model Reliability
Data Preprocessing is ALSO an important step in the Data Preparation stage of a Data Science development lifecycle that will ensure reliable, robust, and consistent results. The main objective of this step is to ensure and check the quality of data before applying any Machine Learning or Data Mining methods.
Let’s review some of its benefits -
Applications of Data Preprocessing
Data Preprocessing is important in the early stages of a Machine Learning and AI application development lifecycle. A few of the most common usage or application include -
Features of data preprocessing
Preprocessing has many features that make it an important preparation step for data analysis. The following are the two main features with a brief explanation:
Whether a business uses database-driven or rules-based applications analysis, preprocessing helps ensure reliable and accurate results when analyzing data. It's important to preprocess data when using machine learning tools to make sure the algorithms can read large datasets and correctly interpret them for further use.
WHAT IS Data Transformation:
Data Transformation: This involves converting the data into a suitable format for analysis. Common techniques used in data transformation include normalization, standardization, and discretization READ- 4 Types of Data - Nominal, Ordinal, Discrete, Continuous (mygreatlearning.com). https://www.mygreatlearning.com/blog/types-of-data/
A. Nominal Data
B. Ordinal Data
Ordinal data have natural ordering where a number is present in some kind of order by their position on the scale.
A. Discrete Data
Examples of Discrete Data :
B. Continuous Data
Continuous data are in the form of fractional numbers. The continuous variable can take any value within a range.
Normalization is used to scale the data to a common range, while standardization is used to transform the data to have zero mean and unit variance. Discretization is used to convert continuous data into discrete categories.
Data Preprocessing Tools
Data preprocessing tools simplify how you interact with extensive data, making it easier to shape and polish complex data. Some data preprocessing tools that make this transformation possible are:
Preprocessing in Data Mining:
Data preprocessing is a data mining technique which is used to transform the raw data in a useful and efficient format.

Steps Involved in Data Preprocessing
How to preprocess data
Some common steps in data preprocessing include:
Data preprocessing techniques
Data preprocessing techniques help you fine-tune data for machine learning models or statistical analysis. Here’s how these techniques help preprocess data:
Data preprocessing is an important step in the data mining process that involves cleaning and transforming raw data to make it suitable for analysis. Some common steps in data preprocessing include:
Data Profiling
Understanding your data is the first step in preprocessing. Data profiling involves examining the data using summary statistics and distributions to understand its structure, content, and quality. This step can reveal patterns, anomalies, and correlations crucial for informed preprocessing.
Example: A retail manager analyzes a dataset of customer purchases to find average spending, most common items, and times of purchase to devise a data-driven marketing strategy.
Conduct a data assessment
Data quality assessment helps determine the accuracy and reliability of the raw data. When assessing the data, you can look for mixed data values, like having both male and man as gender descriptions in the raw data or mismatched data, like having integers without decimals and float formats with decimals. When assessing data, it's important to combine data from separate datasets to ensure that you don't miss important raw data. Extreme data outliers can influence your assessment, especially with machine learning analysis. Consider reviewing any outliers to highlight their accuracy.
Data Cleaning: This involves identifying and correcting errors or inconsistencies in the data, such as missing values, outliers, and duplicates.
Data Cleaning:
The data can have many irrelevant and missing parts. To handle this part, data cleaning is done. It involves handling of missing data, noisy data etc.
(a). Missing Data:
This situation arises when some data is missing in the data. It can be handled in various ways.
Some of them are:
Missing data can skew analysis and lead to inaccurate models. Strategies for handling missing values include imputation (filling in missing values with statistical measures like mean or median) or using algorithms that can handle missing data, such as random forests.
(b). Noisy Data:
Noisy data is a meaningless data that can’t be interpreted by machines.It can be generated due to faulty data collection, data entry errors etc.
Reduce Noisy Data-Noisy data can unclear meaningful patterns. Techniques like smoothing (using rolling averages) and filtering (applying algorithms to remove noise) help clarify the signal in data. For instance, a moving average can smooth out short-term fluctuations and highlight longer-term trends.
It can be handled in following ways :
Data Integration
Data Integration: This involves combining data from multiple sources to create a unified(MEANS UNITED) dataset. Data integration can be challenging as it requires handling data with different formats, structures, and semantics. Techniques such as record linkage and data fusion can be used for data integration.
Data Integration can be defined as combining data from multiple sources. A few of the issues to be considered during Data Integration include the following - Entity Identification Problem - It can be defined as identifying objects/features from multiple databases that correspond to the same entity. For example, in database A _customer_id,_ and in database B _customer_number_ belong to the same entity.
Data Reduction:
Data reduction is a crucial step in the data mining process that involves reducing the size of the dataset while preserving the important information. This is done to improve the efficiency of data analysis and to avoid overfitting of the model. Data Reduction involves reducing the size of the dataset while preserving the important information. Data reduction can be achieved through techniques such as feature selection and feature extraction. Feature selection involves selecting a subset of relevant features from the dataset, while feature extraction involves transforming the data into a lower-dimensional space while preserving the important information.
Some common steps involved in data reduction are:
Feature Selection: This involves selecting a subset of relevant features from the dataset. Feature selection is often performed to remove irrelevant or redundant features from the dataset. It can be done using various techniques such as correlation analysis, mutual information, and principal component analysis (PCA).
Feature Extraction: This involves transforming the data into a lower-dimensional space while preserving the important information. Feature extraction is often used when the original features are high-dimensional and complex. It can be done using techniques such as PCA, linear discriminant analysis (LDA), and non-negative matrix factorization (NMF).
Sampling: This involves selecting a subset of data points from the dataset. Sampling is often used to reduce the size of the dataset while preserving the important information. It can be done using techniques such as random sampling, stratified sampling, and systematic sampling.
Clustering: This involves grouping similar data points together into clusters. Clustering is often used to reduce the size of the dataset by replacing similar data points with a representative centroid. It can be done using techniques such as k-means, hierarchical clustering, and density-based clustering.
Compression: This involves compressing the dataset while preserving the important information. Compression is often used to reduce the size of the dataset for storage and transmission purposes. It can be done using techniques such as wavelet compression, JPEG compression, and gzip compression.
Identify and Remove Duplicates-Duplicate data can distort analysis, leading to biased results. Detection can be as simple as searching for identical records or as complex as identifying near-duplicates using fuzzy matching. Removal ensures each data point is unique, maintaining the integrity of your dataset.
Dimensionality Reduction-Dimensionality reduction techniques, like Principal Component Analysis, lower the variables under consideration, simplifying the model without losing significant information. This method can improve model performance and reduce computational complexity.
A few of the popular techniques to perform Data Reduction include -
Data Transformation
Data Transformation: This involves converting the data into a suitable format for analysis. Common techniques used in data transformation include normalization, standardization, and discretization
Data Transformation is a process of converting data into a format that helps in building efficient ML models and deriving better insights.
This step is taken in order to transform the data in appropriate forms suitable for mining process. A few of the most common methods for Data Transformation include –
Categorical data encoding methods, such as one-hot or label encoding, convert categorical variables (QUALITATIVE) into numerical form for model training. Encoding is essential for algorithms that require numerical input.
Standardization, or mean removal and variance scaling
Standardization of datasets is a common requirement for many machine learning estimators implemented in scikit-learn; they might behave badly if the individual features do not more or less look like standard normally distributed data:
Gaussian with zero mean and unit variance. (Gaussian distribution (also known as normal distribution) is a bell-shaped curve, and it is assumed that during any measurement values will follow a normal distribution with an equal number of measurements above and below the mean value. In order to understand normal distribution, it is important to know the definitions of “mean,” “median,” and “mode.” The “mean” is the calculated average of all values, the “median” is the value at the center point (mid-point) of the distribution, while the “mode” is the value that was observed most frequently during the measurement. If a distribution is normal, then the values of the mean, median, and mode are the same. However, the value of the mean, median, and mode may be different if the distribution is skewed )
In practice we often ignore the shape of the distribution and just transform the data to center it by removing the mean value of each feature, then scale it by dividing non-constant features by their standard deviation.
For instance, many elements used in the objective function of a learning algorithm may assume that all features are centered around zero or have variance in the same order. If a feature has a variance that is orders of magnitude larger than others, it might dominate the objective function and make the estimator unable to learn from other features correctly as expected.
Feature Scaling Scaling features to a uniform range ensures that no single feature dominates the model due to scale. Methods include min-max scaling, which rescales the feature to a fixed range, usually 0 to 1, or standardization, which centers the feature on zero with unit variance.
Scaling features to a range
An alternative standardization is scaling features to lie between a given minimum and maximum value, often between zero and one,
Scaling sparse (scant, little)data
Centering sparse data would destroy the sparseness structure in the data, and thus rarely is a sensible thing to do. However, it can make sense to scale sparse inputs, especially if features are on different scales.
Scaling data with outliers
If your data contains many outliers, scaling using the mean and variance of the data is likely to not work very well.
Mapping to a Uniform distribution
QuantileTransformer provides a non-parametric transformation to map the data to a uniform distribution with values between 0 and 1
Normalization: Data Normalization is a process of converting a numeric variable into a specified range such as [-1,1], [0,1], etc. A few of the most common approaches to performing normalization are Min-Max Normalization, Data Standardization or Data Scaling, etc. It is done in order to scale the data values in a specified range (-1.0 to 1.0 or 0.0 to 1.0) Data Normalization involves scaling the data to a common range, such as between 0 and 1 or -1 and 1. Normalization is often used to handle data with different units and scales. Common normalization techniques include min-max normalization, z-score normalization, and decimal scaling.
IT INCLUDES:
Concept Hierarchy Generation (AGGREGATION): Here attributes are converted from lower level to higher level in hierarchy. For Example-The attribute “city” can be converted to “country”. Data Aggregation is the process of transforming large volumes of data into an organized and summarized format that is more understandable and comprehensive. For example, a company may look at monthly sales data of a product instead of raw sales data to understand its performance better and forecast future sales
Discretization: Data Discretization is a process of converting numerical or continuous variables into a set of intervals/bins. This makes data easier to analyze. For example, the age features can be converted into various intervals such as (0-10, 11-20, ..) or (child, young, …). This is done to replace the raw values of numeric attribute by interval levels or conceptual levels.
Data Discretization involves dividing continuous data into discrete categories or intervals. Discretization is often used in data mining and machine learning algorithms that require categorical data. Discretization can be achieved through techniques such as equal width binning, equal frequency binning, and clustering.
Converting continuous features into discrete bins can make the data more manageable and improve model performance. For example, age can be binned into categories like [1-10] OR ’18-25′, ’26-35′, etc., to simplify analysis and reveal generational trends.
Suppose we have an attribute of Age with the given values
|
Age |
1,5,9,4,7,11,14,17,13,18, 19,31,33,36,42,44,46,70,74,78,77 |
|
Attribute |
Age |
Age |
Age |
Age |
|
1,5,4,9,7 |
11,14,17,13,18,19 |
31,33,36,42,44,46 |
70,74,77,78 |
|
|
After Discretization |
Child |
Young |
Mature |
Old |
Another example is analytics, where we gather the static data of website visitors. For example, all visitors who visit the site with the IP address of India are shown under country level.
Some Famous techniques of data discretization
1Histogram analysis-Histogram refers to a plot used to represent the underlying frequency distribution of a continuous data set. Histogram assists the data inspection for data distribution. For example, Outliers, skewness representation, normal distribution representation, etc.
2Binning-Binning refers to a data smoothing technique that helps to group a huge number of continuous values into smaller values. For data discretization and the development of idea hierarchy, this technique can also be used.
3Cluster Analysis-Cluster analysis is a form of data discretization. A clustering algorithm is executed by dividing the values of x numbers into clusters to isolate a computational feature of x.
Enhancing data with additional sources or derived attributes can provide more depth and context. It involves incorporating demographic information into customer data or adding weather data to sales figures to account for seasonal effects.
Example: A data analyst adds weather data to a retailer’s sales data to see if weather patterns affect buying trends.
Before moving on to analysis, it’s crucial to ensure the integrity of your data. Data validation checks that the data meets specific criteria, such as constraints, relations, and ranges. It helps to confirm that the data is accurate, complete, and reliable.
Example: A finance executive checks whether all entries in a transaction dataset fall within expected date ranges and transaction amounts.
Data preprocessing plays a crucial role in ensuring the quality of data and the accuracy of the analysis results. The specific steps involved in data preprocessing may vary depending on the nature of the data and the analysis goals. By performing these steps, the data mining process becomes more efficient and the results become more accurate.
Data Cleaning vs Data Preprocessing
While often used interchangeably, data cleaning and data preprocessing are not the same. Data cleaning is a subset of preprocessing, primarily concerned with identifying and correcting errors and inconsistencies within the dataset. On the other hand, data preprocessing is an umbrella term that includes data cleaning and other processes such as normalization, transformation, and feature extraction, which are essential to prepare data for analysis.
Data Exploration vs Data Preprocessing
Data exploration is like detective work, where you look for patterns, anomalies, and insights within the data. It involves asking questions and getting answers through visual and quantitative methods. Data preprocessing, however, is the groundwork that makes such exploration possible. It involves cleaning, transforming, and organizing data to be effectively explored and analyzed for meaningful insights.
Data Preparation vs Data Preprocessing
Data preparation and data preprocessing are also used synonymously, but they can have different connotations. Data preparation can be a broader category, including preprocessing, data collection, and integration. It encompasses the entire process of getting data ready for analysis, from when it’s gathered to when it’s fed into analytical tools. Data preprocessing, while part of the preparation, is specifically focused on transforming and conditioning data before analysis.
professionals that use preprocessing
IT professionals across various industries use data analysis to perform their tasks at work, which also requires them to preprocess data. The following are some professionals that use preprocessing of data:
Data analyst
Data analysts specialize in analyzing and interpreting large datasets to help businesses make accurate and informed decisions about their day-to-day activities or new projects. They interpret raw data and transform it into accurate and meaningful information that can help businesses make predictions about their products, employees, projects, and industry. Data analysts are often proficient statisticians skilled in equation and data interpretation, which help them identify and analyze trends or predict outcomes.
Data scientist
Data scientists are important to any business or organization. They typically possess extensive knowledge of computer programming, data analysis, and business knowledge. They also often have the relevant industry experience to analyze data and help businesses, organizations, or individuals make accurate decisions. A data scientist may work in politics and interpret polling data to help predict election results or voting trends.
Machine learning engineer
A machine learning engineer specifically works with machine learning algorithms by ensuring that they function effectively on their own. They may choose to work in various industries, like social media, e-commerce, transportation, aviation, and coding. Machine learning engineers work with other IT professionals to program and train artificial intelligence (AI) platforms that cater to a business's various requirements.
Software developer
A software developer builds and designs software applications, platforms, and tools that enable individuals and businesses to perform their tasks efficiently and effectively. They create applications for smartphones, computers, tablets, and other devices that can help businesses and individuals conduct trade, communicate with other professionals, view weather forecasts, consume media, and shop online. Software developers have detailed knowledge about data and are often skilled in preprocessing data for analysis.
Examples of preprocessing data
Here are some examples of how preprocessing data can benefit companies in various fields:
Important for web mining: Businesses can use web usage logs and preprocess the data to identify users' browsing habits and the websites and products they viewed, and give them better recommendations based on that data. Preprocessing data is important for activities like customer research, marketing, and advertisement personalization.
Data Preprocessing in Data Mining: A Comprehensive Guide
Data preprocessing is a crucial step in the data mining process. It involves cleaning, transforming, and organizing raw data to prepare it for analysis. The goal? To enhance data quality and make it more suitable for specific data mining tasks. Buckle up—we’re about to explore the key techniques and concepts!
1. Data Cleaning:
2. Data Integration:
3. Data Transformation:
4. Data Reduction:
5. Data Discretization:
6. Data Normalization:
Remember, these steps are interconnected, and the order may vary based on your specific problem. Data preprocessing ensures cleaner, more reliable results when you apply machine learning algorithms or statistical analyses.
What are the Implementations of Data Warehouse?
Data warehouses contain huge volumes of data. OLAP servers demand that decision support queries be acknowledged in the order of seconds. Thus, it is essential for data warehouse systems to provide highly effective cube computation techniques, access techniques, and query processing techniques.
What Are Data Cubes?
Example:
Suppose we have sales data for AllElectronics, with dimensions: city, item, and year, and a measure: sales in dollars. The data cube would look like this:
The possible group-by’s (cuboids) for this data cube are:
Here, () represents the empty group-by (no dimensions grouped).
Challenges:
Methods for Efficient Data Cube Computation
1. Materialized Views:
2. Multiway Array Aggregation (MultiWay):
3. BUC (Bottom-Up Computation):
Conclusion
Efficient data cube computation is essential for data warehouse systems. Whether through materialized views, specialized operators, or smart aggregation techniques, optimizing data cube computation enhances OLAP performance.
\
Que 1. Explain Data Cube Computation: Preliminary Concepts
Explain Cube Materialization: 1. Full Cube 2. Iceberg cube 3. Closed Cube 4. Cube Shell.
Data Cube :
Data Cube Computation :
Why data cube computation is needed?
Cube Materialization (pre-computation):
Different Data Cube materialization include.
1. The Full cube:
Advantage:
Disadvantage:
2. An Iceberg-Cube:
Advantage:
3. A Closed Cube:
4. Shell Cube:
In the context of data cubes used in OLAP (Online Analytical Processing) and data warehousing, Closed Cubes and Shell Cubes are two different strategies for cube materialization:
Both strategies aim to optimize the performance and efficiency of data cube computations but differ in their approach to materialization and storage.
Que 2. What are the general optimization techniques for efficient computation of data cubes.
Data Cube Computation:
1. Multiway Array Aggregation for full Cube Computation:
1. Partition the array into chunks.
A chunk is a sub-cube that is fit into the memory available for cube computation. Chunking is a method for dividing an A-dimension array into small n-dimensional chunks, where each chunk is stored as an object on a disk. The chunks are compressed so as to remove wasted space resulting from empty array cells. For instance, “chunk ID + offset” can be used as a cell addressing mechanism to compress a sparse array structure and when searching for cells within a chunk. Such a compression technique is powerful enough to handle sparse cubes, both on disk and in memory.
2. Compute aggregates by visiting (i.e., accessing the values at) cube cells.
The order in which cells are visited can be optimized so as to minimize the number of times that each cell must be revisited, thereby reducing memory access and storage costs. The trick is to exploit this ordering so that partial aggregates can be computed simultaneously, and any unnecessary revisiting of cells is avoided. Because this chunking technique involves “overlapping” some of the aggregation computations, it is referred to as multiway array aggregation. It performs simultaneous aggregation, that is, it computes aggregations simultaneously on multiple dimensions.
2. BUC: Computing Iceberg Cubes from the Apex Cuboid Downward:
 BUC’s exploration for a 3-D data cube computation. Note that the computation starts from the apex cuboid.
BUC’s exploration for a 3-D data cube computation. Note that the computation starts from the apex cuboid.
Algorithm: BUC algorithm for the computation of sparse and iceberg cubes.
BUC Algorithm Explanation:
3. Explain Computing Iceberg Cubes Using a Dynamic Star-Tree Structure:
 Star-Cubing: bottom-up computation with top-down expansion of shared dimensions.Base cuboid tree fragment.
Star-Cubing: bottom-up computation with top-down expansion of shared dimensions.Base cuboid tree fragment.
4. Describe Precomputing Shell Fragments for Fast High-Dimensional OLAP.
Que 3. Explain OLAP-Based Mining on Sampling Data (Sampling Cubes).
Sampling Cubes:
Efficient Computation of Data Cubes (youtube link: Efficient data cube computation. Partial Materialization (youtube.com))
At the core of multidimensional data analysis is the efficient computation of aggregations across many sets of dimensions. In SQL terms, these aggregations are referred to as group-by’s. Each group-by can be represented by a cuboid, where the set of group-by’s forms a lattice of cuboids defining a data cube. (A cuboid is a three dimensional solid that has 6 faces (rectangular), 8 vertices and 12 edges. A cuboid has three dimensions such as length, width and height. )
Data Warehouse Implementation
The big data which is to be analyzed and handled to draw insights from it will be stored in data warehouses.
These warehouses are run by OLAP servers which require processing of a query with seconds.
So, a data warehouse should need highly efficient cube computation techniques, access methods, and query processing techniques.
The core of multidimensional data analysis is the efficient computation of aggregations across many sets of dimensions.
In SQL aggregations are referred to as group-by’s.
Each group-by can be represented as a cuboid.
Set of group-by’s forms a lattice (framework or a matrix) of a cuboid defining a data cube.
Efficient Data Cube Computation
Introduction To Data Cube Computation And It’s Types
Data science is a rapidly growing field that deals with the extraction of insights and knowledge from data. One of the most important tools used by data scientists is the data cube, which allows them to analyze large datasets and extract valuable information. In this blog post, we will explore what data cubes are, how they are used in both data warehousing and mining, and various methods for computing them. For an in-depth understanding of data cube computation,
What is a Data Cube?
A Data cube can be defined as a multi-dimensional array that stores aggregated information about different aspects of a dataset. It provides an efficient way to summarize large amounts of information into smaller sets that can be easily analyzed. The dimensions in a data cube represent different attributes or variables within the dataset while each cell contains an aggregate value such as sum, count or average.
Data Cube in Data Mining
In contrast to OLAP cubes created for business intelligence purposes, those created for mining purposes focus on discovering hidden patterns within datasets rather than simply summarizing it. These types of cubes are often referred to as Concept Hierarchies because they group similar items together based on shared characteristics or behaviors. Data cube computation is the process of transforming raw data into multidimensional views, or "cubes," for efficient analysis and exploration. By organizing data into dimensions and measures, data cube computation enables users to drill down or roll up data, filter and group data based on various criteria, and identify trends and patterns that may not be visible in traditional reports.
Data cube computation is a critical component of data warehousing and business intelligence, enabling organizations to unlock the insights hidden within their data and gain a competitive edge in the marketplace
What is Data Cube Computation?
Data cube computation is an important step in the process of creating a data warehouse. Depending on your requirements, full or partial data cube pre-computation can greatly improve the reaction time and performance of online analytical processing. Performing such a computation, however, may be difficult because it may take a significant amount of time and room on the computer. Multidimensional data can be examined in real-time using data cubes. The process of shifting a significant amount of information in a database that is relevant to a particular job from a low level of abstraction to a higher one is known as Data Generalization. It is extremely helpful and convenient for users to have large data sets depicted in simple terms, at varied degrees of granularity, and from a variety of perspectives (means views). This saves users a great deal of time. These kinds of data summaries are helpful because they provide a picture that encompasses the entire set of facts.
Through the use of cube in data warehouse and Online Analytical Processing (OLAP), one can generalize data by first summarizing it at multiple different levels of abstraction. For example, a retail company may use a data cube to analyze their sales data across different dimensions such as product categories, geographical locations, and time periods. By doing so, they can identify which products are selling the most in specific regions or during certain times of the year. This information can then be used to make more informed decisions about inventory management and marketing strategies.
Data Cube in Data Mining
In addition to its use in data warehousing, data cubes also play an important role in data mining. Data mining is the process of discovering patterns and relationships within large datasets that cannot be easily identified through manual analysis. One common technique used in data mining is association rule mining which involves identifying co-occurring items within a dataset.
A Data Cube makes it easier to perform association rule mining by allowing analysts to group items based on multiple dimensions simultaneously. For example, an e-commerce website may use a data cube to analyze customer transactional records across different dimensions such as product categories, customer demographics, and purchase frequency. By doing so, they can identify which products are frequently purchased together by specific groups of customers.
Methods For Data Cube Computation?
1) Materialization of Cube: Full, Iceberg, Closed and Shell Cubes
A three-dimensional data cube with dimensions A, B, and C and an aggregate measure M. You can think of a data cube as a lattice of cuboids. Each cube is meant to symbolize a group. The fundamental cuboid, encompassing all three dimensions, is the ABC. The aggregate measure (M) is calculated for each permutation of the three dimensions. There are six different cuboids that make up a data cube, with the base cuboid being the most specific. The apex cuboid (at the top) is the most generalized cuboid. It stores a single number - the sum of all the tuples' measures in the base cuboid's measure M. From the topmost cuboid of the data cube example, we can descend into the lattice to access deeper levels of information.

Lattice of cuboids that make upa 3-D data cube with A, B, C dimensions for an aggregate measure M When rolling up, one begins at the bottom cube and works one's way up. For the rest of this chapter, whenever we speak to a data cube definition, we mean a lattice of cuboids rather than a single cuboid.
Base Cell In Data Cube
The term "base cell" refers to a cell in the base cuboid. Aggregate cells are cells that are not based on a cube. Each dimension that is aggregated in an aggregate cell is represented by a "" in the cell notation. Let's pretend we're working with an n-dimensional data cube. Let each cell of the cuboids that make up the data cube be denoted by a = (a1, a2,..., an, measurements). If there are m (m n) values of a, b, c, d, e, f, g, h, I j, k, l, m, n, and o that are not "," then we say that an is an m-dimensional cell (that is, from an m- A is a base cell if and only if m = n; otherwise, it is an aggregate cell (where m n).
On occasion, it is desirable to precompute the whole cube to ensure rapid on-line analytical processing (i.e., all the cells of all of the cuboids for a given data cube). The complexity of this task, however, grows exponentially with the number of dimensions. In other words, there are 2n cuboids inside an n-dimensional data cube. When we include in the concept hierarchies for each dimension, the number of cuboids grows much larger. 1Additionally, the size of each cuboid is determined by the cardinality of its dimensions. Therefore, it is not uncommon for precomputation of the whole cube to necessitate vast and frequently excessive quantities of memory. Still, algorithms that can calculate a whole cube are crucial. Secondary storage can be used to keep individual cuboids out of the way, until they're needed. Alternatively, we can use these techniques to compute cubes with fewer dimensions, or dimensions with narrower ranges of values. For some range of dimensions and/or dimension values, the smaller cube is a complete cube.We can create effective methods for computing partial cubes if we have a firm grasp on how whole cubes are computed. Therefore, it is crucial to investigate scalable approaches for fully materializing a data cube, i.e., calculating all of the cuboids that comprise it. These techniques need to think about the time and main memory constraints associated with cuboid calculation, as well as the total size of the data cube that will be computed.
Cuboids In Data Cube
As an intriguing compromise between storage requirements and response times for OLAP, data cubes that are partially materialized are a viable option. We cannot compute the entire data cube, but rather only parts of it, called cuboids, each of which is composed of a subset of the cells in the full cube.
Data analysts may find that many cube cells contain information that is of little use to them. You may recall that a complete cube's cells all contain summative values. Numbers, totals, and monetary sales figures are popular units of measurement. The measure value for many cuboid cells is zero. We say that a cuboid is sparse when the number of non-zero-valued tuples stored in it is small compared to the product of the cardinalities of the dimensions stored in it. One defines a cube as sparse if it is made up of several sparse cuboids.A huge number of cells with extremely small measure values can take up a lot of room in the cube. This is due to the fact that cube cells in an n-dimensional space are typically relatively spread out. In a store, a consumer might only buy a few goods at a time. It's likely that this kind of thing would only produce a handful of full cube cells. When this occurs, it can be helpful to only materialize the cuboid cells (group-by) whose measure value is greater than a predetermined threshold. Say we have a data cube for sales, and we only care about the cells where the count is greater than 10 (i.e., when at least 10 tuples exist for the cell's given combination of dimensions), or the cells where the sales amount is greater than $100.
Minimum Support And Iceberg In Data Cube
Not only does this result in a more effective utilization of resources (namely, CPU time and disc space), but it also makes it possible to conduct more accurate analysis. There is a good chance that the non-passing cells are not important enough to warrant further investigation. Cubes that only partially materialize are referred to as iceberg cubes, and this phrase is used to characterize such cubes. The term "minimum support," also abbreviated as "min sup" for short, describes the criteria that are the absolute minimum acceptable. It is common practise to refer to the effect of materializing only a fraction of the cells in a data cube as the "tip of the iceberg (not entire)." In this context, "iceberg" refers to the entire cube including all cells.
A naïve technique to computing an iceberg cube would be to first calculate the full cube and then prune the cells that do not satisfy the iceberg requirement. However, this is still unreasonably expensive. To save time, it is possible to compute simply the iceberg cube directly instead of the whole cube. The introduction of iceberg cubes simplifies the computation of inconsequential aggregate cells in a data cube. Nonetheless, it is possible that we will have a significant number of boring cells to process.
The idea of closed coverage needs to be introduced if we are to compress a data cube in a systematic manner. If there is no cell d such that d is a specialization (descendant) of c (obtained by substituting a in c with a non- value) and d has the same measure value as c, then c is said to be closed. All of the cells in a data cube are considered closed in a closed cube. For the data set [(a1, a2, a3,..., a100): 10], the three cells [(b1, b2, b3,..., b100): 10][[a1, b2, b3,..., b100]] are the three closed cells of the data cube. They make up the lattice of a closed cube, from the equivalent closed cells in this lattice, other non-closed cells can be constructed. It is possible to infer "(a1, a2, b3,...): 10" from "(a1, a2, b3,...): 10" because "(a1, a2, b3,...): 10" is a generalized non-closed cell of "(a1, a2, b3,...): 10".As another method of partial materialization, precomputing only the cuboids involving a small number of dimensions, say, 3 to 5, is feasible. When placed together, these cuboids create a cube shell around the associated data cube. Any more dimension-combination queries will require on-the-fly computation. In an n-dimensional data cube, for instance, we could compute all cuboids of dimension 3 or smaller, yielding a cube shell of dimension 3.

Three closed cells forming the lattice of a closed cube However, when n is large, this can still lead to a very large number of cuboids to compute. Alternatively, we can select subsets of cuboids of interest and precompute only those subshells. Such shell fragments and a method for computing them are discussed in.
2) Roll-up/Drill-down- This method involves aggregating data along one or more dimensions to create a summary of the dataset. It can be used to drill-down into specific areas of interest within the data. Roll-up/Drill-down is useful for quickly summarizing large datasets into manageable chunks while still maintaining important information about each dimension. For example, if you have sales data for multiple products across several regions, you could use roll-up/drill-down to see total sales across all regions or drill-down into sales numbers for one particular product in one region.
3) Slice-and-Dice - This method involves selecting subsets of data based on certain criteria and then analyzing it using different dimensions. It is useful for identifying patterns that may not be immediately apparent when looking at the entire dataset.Slice-and-Dice allows users to select subsets of data based on specific criteria such as time period or customer demographics which can then be analyzed using different dimensions like product categories or geographic locations. This helps identify patterns that may not be immediately apparent when looking at the entire dataset.
4) Grouping Sets - This method involves grouping data by multiple dimensions at once, allowing for more complex analysis of the dataset.Grouping Sets are useful when analyzing large datasets with multiple dimensions where users want to group by two or more dimensions at once. For example, grouping sets could show total revenue broken down by both product category and region simultaneously.
5) Online Analytical Processing (OLAP) - This method uses a multidimensional database to store and analyze large amounts of data. It allows for quick querying and analysis of the data in different ways.OLAP databases are specifically designed for analyzing large amounts of multi-dimensional data quickly through pre-aggregated values stored in memory making it ideal for real-time decision-making scenarios like stock market analysis.
6) SQL Queries - SQL queries can be used to compute data cubes by selecting specific columns and aggregating them based on certain criteria. This is a flexible method that can be customized based on the needs of the user.SQL queries provide flexibility regarding how much control users have over what they want from their cube as well as customization options such as adding additional calculations or filtering data based on specific criteria. SQL queries are ideal when users have a good understanding of the underlying dataset and want to customize their analysis in real-time.
Materialized Views are useful when dealing with small datasets or when computing time isn't an issue. However, as datasets become larger and more complex, materializing views becomes less feasible due to storage limitations and computation time.
The compute cube Operator and the Curse of Dimensionality
The compute cube operator computes aggregates over all subsets of the dimensions specified in the operation.
It requires excessive storage space, especially for a large number of dimensions.
A data cube is a lattice of cuboids.
Suppose that we create a data cube for ProElectronics(Company) sales that contains the following: city, item, year, and sales_in_dollars.
Compute the sum of sales, grouping by city, and item.
Compute the sum of sales, grouping by city.
Compute the sum of sales, grouping by item.
What is the total number of cuboids, or group-by’s, that can be computed for this data cube?
Three attributes:
city, item, year (dimensions), sales_in_dollars (measure).
The total number of cuboids or group-by’s computed for this cube is 2^3=8.
Group-by’s: {(city,item,year), (city, item), (city, year), (item, year), (city), (item), (year),()}.
() : group-by is empty i.e. the dimensions are not grouped.
The base cuboid contains all three dimensions.
Apex cuboid is empty.
On-line analytical processing may need to access different cuboids for different queries.
So we have to compute all or at least some of the cuboids in the data cube in advance.
Precomputation leads to fast response time and avoids some redundant computation.
A major challenge related to precomputation would be storage space if all the cuboids in the data cube are computed, especially when the cube has many dimensions.
The storage requirements are even more excessive when many of the dimensions have associated concept hierarchies, each with multiple levels.
This problem is referred to as the Curse of Dimensionality.
Cube Operation

Cube definition and computation in DMQL
Transform it into a SQL-like language (with a new operator cube by, introduced by Gray et al.’96)
Data cube can be viewed as a lattice of cuboids
Data Cube Materialization
There are three choices for data cube materialization given a base cuboid.
How to select which materialization to use
Selection of which cuboids to materialize
Indexing OLAP Data: Bitmap Index
First of all, create an index table on a particular column of the table.
Then each value in the column has got a bit vector: bit-op is fast.
The length of the bit vector: # of records in the base table.
The i-th bit is set if the i-th row of the base table has the value for the indexed column.
It's not suitable for high cardinality domains.

Indexing OLAP Data: Join Indices
The join indexing method gained popularity from its use in relational database query processing.
The join index records can identify joinable tuples without performing costly join operations.
Join indexing is especially useful for maintaining the relationship between a foreign key and its matching primary keys, from the joinable relation.

Suppose that there are 360-time values, 100 items, 50 branches, 30 locations, and 10 million sales tuples in the sales star data cube. If the sales fact table has recorded sales for only 30 items, the remaining 70 items will obviously not participate in joins. If join indices are not used, additional I/Os have to be performed to bring the joining portions of the fact table and dimension tables together.
To further speed up query processing, the join indexing, and bitmap indexing methods can be integrated to form bitmapped join indices.
Microsoft SQL Server and Sybase IQ support bitmap indices. Oracle 8 uses bitmap and join indices.
Efficient Processing OLAP Queries
The purpose of materializing cuboids and constructing OLAP index structures is to speed up the query processing in data cubes.
Given materialized views, query processing should proceed as follows:
Determine which operations should be performed on the available cuboids:
Determine to which materialized cuboid(s) the relevant operations should be applied:
Summary
Efficient computation of data cubes:
There are three choices for data cube materialization given a base cuboid −
Indexing OLAP Data
It can support efficient data accessing, some data warehouse systems provide index structures and materialized views (using cuboids). The bitmap indexing approaches is famous in OLAP products because it enables fast searching in data cubes. The bitmap index is an alternative representation of the record ID (RID) list.
In the bitmap index for a given attribute, there is a distinct bit vector, Bv, for each value v in the domain of the attribute. If the domain of a given attribute includes n values, then n bits are required for each entry in the bitmap index (i.e., there are n bit vectors). If the attribute has the value v for a given row in the data table, then the bit defining that value is set to 1 in the corresponding row of the bitmap index. All other bits for that row are set to 0.
Efficient Processing of OLAP Queries
The goals of materializing cuboids and constructing OLAP index structures is to speed up query processing in data cubes.
General Strategies for Data Cube computation in Data Mining
Pre-requisites: Data mining
Data Mining can be referred to as knowledge mining from data, knowledge extraction, data/pattern analysis, data archaeology, and data dredging. In data mining, a data cube is a multi-dimensional array of data that is used for online analytical processing (OLAP).
Here are a few strategies for data cube computation in data mining:
1. Materialized view
This approach involves pre-computing and storing the data cube in a database. This can be done using a materialized view, which is a pre-computed table that is based on a SELECT statement.
2. Lazy evaluation
This approach involves delaying the computation of the data cube until it is actually needed.
3. Incremental update
This approach involves computing the data cube incrementally, by only updating the parts of the data cube that have changed.
4. Data cube approximation
This approach involves approximating the data cube using sampling or other techniques.
5. Data warehouse
A data warehouse is a central repository of data that is designed for efficient querying and analysis. Data cubes can be computed on top of a data warehouse, which allows for fast querying of the data. However, data warehouses can be expensive to set up and maintain, and may not be suitable for all organizations.
6. Distributed computing
In this approach, the data cube is computed using a distributed computing system, such as Hadoop or Spark.
7. In-memory computing
This approach involves storing the data in memory and computing the data cube directly from memory.
8. Streaming data
This approach involves computing the data cube on a stream of data, rather than a batch of data.
Note: Sorting, hashing, and grouping are techniques that can be used to optimize data cube computation, but they are not necessarily strategies for data cube computation in and of themselves.
Distributed Data Warehouses
The concept of a distributed data warehouse suggests that there are two types of distributed data warehouses and their modifications for the local enterprise warehouses which are distributed throughout the enterprise and a global warehouses as shown in fig:

Characteristics of Local data warehouses
Virtual Data Warehouses
Virtual Data Warehouses is created in the following stages:
This strategy defines that end users are allowed to get at operational databases directly using whatever tools are implemented to the data access network. This method provides ultimate flexibility as well as the minimum amount of redundant information that must be loaded and maintained. The data warehouse is a great idea, but it is difficult to build and requires investment. Why not use a cheap and fast method by eliminating the transformation phase of repositories for metadata and another database. This method is termed the 'virtual data warehouse.'
To accomplish this, there is a need to define four kinds of data:
Disadvantages

A virtual warehouse can scale out on demand. It can provide resources such as CPU, memory, and temporary storage. These resources are key in performing the following operations:
Advantages of Virtual Warehouses
Virtual warehouses have the following advantages:
Enterprise warehouse and virtual warehouse
There are three models of data warehouses from an architecture point of view: enterprise warehouse, data mart, and virtual warehouse.
Data virtualisation vs. data warehouse
The key benefit of data virtualisation is that it allows us to construct a solution in a fraction of the time it takes to establish a data warehouse.

Data virtualisation has alternative names such as physical data warehouse, data federation, virtual database, and decentralised data warehouse. Data virtualisation enables organisations to integrate data from various sources, keeping the data in-place so that you can generate reports and dashboards to create business value from the data. It is an alternative approach to building a data warehouse, where you collect data from various sources and store a copy of the data in a new data store.
Unlike a data warehouse, data virtualisation does not require data to be stored in a single database repository. It virtualises an organisation’s siloed data from multiple sources into a single, unified data view from which a variety of BI tools can draw insights. Data is accessed in its native or original form “as is” but appears as a unified data warehouse to users.
The birth of the relational data warehouse in the early 1990s drove an enormous amount of innovation and revolutionised the way businesses managed data. Making data available to users in one single database repository with a query interface (SQL) was a game-changer. The ability to draw insights from different physical systems created new opportunities to improve business operations and create value.
Difference between distributed and virtual data warehouse
Virtual data warehouse or data virtualisation refers to a layer that sits on top of existing databases and enables the user to query all of them as if they were one database (although they are logically and physically separated).
Distributed data warehouse refers to the physical architecture of a single database. The data in the warehouse is integrated across the enterprise, and an integrated view is used only at central location of the enterprise. The enterprise operates on a centralised business model.
Go through
Data Warehousing Basics
What Is a Data Warehouse?
A data warehouse (or enterprise data warehouse, EDW) is a system that aggregates data from various sources into a single, central, consistent data store. Its purpose is to support data analysis, data mining, artificial intelligence (AI), and machine learning. Here are the key points:
Traditionally, data warehouses were hosted on-premises, often on mainframe computers. However, modern data warehouses can be hosted on dedicated appliances or in the cloud. Let’s dive deeper into two specific types: distributed data warehouses and virtual data warehouses.
Distributed Data Warehouse
A distributed data warehouse is a type of database management system that stores data across multiple computers or sites connected by a network. Here’s what you need to know:
A distributed data warehouse is a type of database management system that stores data across multiple computers or sites connected by a network. Unlike traditional centralized data warehouses, where all data resides in a single location, distributed data warehouses distribute data storage and processing across various nodes. Here are the key points:
Advantages of Distributed Data Warehouses:
Disadvantages of Distributed Data Warehouses:
Virtual Data Warehouse
A virtual data warehouse (also known as data virtualization) is a layer that sits on top of existing databases. Here’s how it works:
A virtual data warehouse (also known as data virtualization) is a layer that sits on top of existing databases. It provides a unified view of data from various sources without physically moving or replicating the data. Here’s how it works:
Advantages of Virtual Data Warehouses:
Disadvantages of Virtual Data Warehouses:
Key Differences
In summary, distributed data warehouses focus on physical distribution, while virtual data warehouses emphasize logical integration. Both play crucial roles in modern data management, catering to different use cases and scalability needs.
A Data Warehouse is separate from DBMS, it stores a huge amount of data, which is typically collected from multiple heterogeneous sources like files, DBMS, etc.
Issues Occur while Building the Warehouse
When and how to gather data: In a source-driven architecture for gathering data, the data sources transmit new information, either continually (as transaction processing takes place), or periodically (nightly, for example). In a destination-driven architecture, the data warehouse periodically sends requests for new data to the sources. Unless updates at the sources are replicated at the warehouse via two phase commit, the warehouse will never be quite up to-date with the sources. Two-phase commit is usually far too expensive to be an option, so data warehouses typically have slightly out-of-date data. That, however, is usually not a problem for decision-support systems.
What schema to use: Data sources that have been constructed independently are likely to have different schemas. In fact, they may even use different data models. Part of the task of a warehouse is to perform schema integration, and to convert data to the integrated schema before they are stored. As a result, the data stored in the warehouse are not just a copy of the data at the sources. Instead, they can be thought of as a materialized view of the data at the sources.
Data transformation and cleansing: The task of correcting and preprocessing data is called data cleansing. Data sources often deliver data with numerous minor inconsistencies, which can be corrected. For example, names are often misspelled, and addresses may have street, area, or city names misspelled, or postal codes entered incorrectly. These can be corrected to a reasonable extent by consulting a database of street names and postal codes in each city. The approximate matching of data required for this task is referred to as fuzzy lookup.
How to propagate update: Updates on relations at the data sources must be propagated to the data warehouse. If the relations at the data warehouse are exactly the same as those at the data source, the propagation is straightforward. If they are not, the problem of propagating updates is basically the view-maintenance problem.
What data to summarize: The raw data generated by a transaction-processing system may be too large to store online. However, we can answer many queries by maintaining just summary data obtained by aggregation on a relation, rather than maintaining the entire relation. For example, instead of storing data about every sale of clothing, we can store total sales of clothing by item name and category.
Need for Data Warehouse
An ordinary Database can store MBs to GBs of data and that too for a specific purpose. For storing data of TB size, the storage shifted to the Data Warehouse. Besides this, a transactional database doesn’t offer itself to analytics. To effectively perform analytics, an organization keeps a central Data Warehouse to closely study its business by organizing, understanding, and using its historical data for making strategic decisions and analyzing trends.
Benefits of Data Warehouse
Better business analytics: Data warehouse plays an important role in every business to store and analysis of all the past data and records of the company. which can further increase the understanding or analysis of data for the company.
Faster Queries: The data warehouse is designed to handle large queries that’s why it runs queries faster than the database.
Improved data Quality: In the data warehouse the data you gathered from different sources is being stored and analyzed it does not interfere with or add data by itself so your quality of data is maintained and if you get any issue regarding data quality then the data warehouse team will solve this.
Historical Insight: The warehouse stores all your historical data which contains details about the business so that one can analyze it at any time and extract insights from it.
In simple terms, a data warehouse is a warehouse of data of an organization where the collected data is stored. This data is analyzed and is turned into information required for the organization. It is a place where data is stored for a longer period of duration. It is also represented as DW in short. Data warehouse is a good place to store historical data which is a result of daily transactional data and other data sources. Data warehouse is an important part of the business intelligence infrastructure of a company.
It is a relational database using which query and analysis can be performed. Data in the data warehouse is used for creating reports. These reports support the decision-making required by the business intelligence department of the company. Data is extracted, transformed, and loaded (ETL) from operational systems to the warehouse which is used for analysis and creating business reports. These tools are also referred to as business intelligence tools.

A number of ETL tools are available for this purpose. The data can be stored in the staging area till it is loaded in the data warehouse. The data in the warehouse can be arranged into a combination of facts and dimensions called start schema. From the warehouse, the data can be further divided into data marts as per the functions of the business.
Data warehouse has taken many years to evolve. It evolved from DSS (Decision Support Systems) and information processing. The whole period started from the year 1960 till 1980. Bill Inmon is called the father of data warehousing concepts. In the early 1960s, magnetic tapes were used to store master files, punched cards were used and applications were built in COBOL. Thus punched cards, paper tapes, magnetic tapes, and disk storage systems were used for holding data. However, the drawback was that the data had to be accessed sequentially and this also used to take more time.

In the mid-1960s, due to the growth of master files, data redundancy increased. This caused a number of problems as the complexity of maintaining programs was increased. There was a need for hardware to support the master files. It was getting difficult and complex to develop new programs. This has aroused the need of data synchronization after updation.
In 1970, there came the concepts of disk storage and DASD (Direct Access Storage Devices). The advantage of this technology was that there was a facility of direct access and the time consumption was also much less.
[DASD led to the development of DBMS (Database Management System) where access, storage, and indexing of data became very easy on DASD. DBMS has the ability to locate data quickly. After DBMS came the Database which was the single source of data for all processing.]
In the mid-1970s, there came a concept of OLTP (Online Transaction Processing) which resulted in faster access of data than before. This came out to be very beneficial for information processing in the business. Computers were used for reservation systems. Other examples include manufacturing control systems and bank teller systems.
In the 1980s, PC or 4GL Technology (Fourth Generation Languages) was developed. In this technology, the end user had direct control over data and systems. There came the concept of MIS (Management Information System) which is used for management decisions and is now called as DSS. At the time, a single database is available for all the purposes.
In 1985, the concept of an extract program was available using which one can search for a query in the database and get the result. It is straightforward to use and delivers high performance. In this process, one searches through a file or a database according to a particular query or criterion. After finding the result, the data is transported to another file or database. Here, the end user can have good control over the system.
Using the extract program was simple to search a query in a database. But it became difficult to process large number of extracts per day. There were extracts of extracts of extracts of extracts and so on. This process is also known as naturally evolving architecture.
Drawbacks:
Then there was a transition from spider’s web environment to data warehouse environment. Spider’s web development can lead to operational database or DSS-
There are 4 important characteristics of data warehouse. It is subject-oriented, integrated, non-volatile and time-variant.

Data warehouse of an organization is subject-oriented. Each company has its own applications and subject areas. For example, an insurance company has customer, policy, premium and claim as some of the subject areas. A retailer has product, sale, vendor etc. as the major subject areas.

It is the most important characteristic of data warehouse. Data is transferred from operational environment to data warehouse environment after integration.
Before transfer, the operational data is not integrated and requires conversion, formatting, summarizing and re-sequencing etc. It gives an enterprise view of data. The data is looked as if it has come from a single well-defined source.
The data in the data warehouse is non-volatile which means once the data is entered, it cannot be updated.

Every unit of data is accurate at one moment in time. The data keeps on varying with time but every data is considered to be accurate at the moment it is recorded.
Data Warehouses are a significant asset in today’s data-driven business environment. Here’s why:
However, like any technology, Data Warehouses come with their own set of challenges:
It helps in detecting credit card fraud analysis. It is helpful in inventory management. One can get to know the customer profile as well.
The disadvantages of a data warehouse are that it leads to the integration of data from the old legacy environment. It results in large volumes of data.
 By Soha jamil – Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=46448452
By Soha jamil – Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=46448452
There are 4 kinds of data warehouses:
Features of Data Warehousing (not data warehouse)
Data warehousing is essential for modern data management, providing a strong foundation for organizations to consolidate and analyze data strategically. Its distinguishing features empower businesses with the tools to make informed decisions and extract valuable insights from their data.
Centralized Data Repository: Data warehousing provides a centralized repository for all enterprise data from various sources, such as transactional databases, operational systems, and external sources. This enables organizations to have a comprehensive view of their data, which can help in making informed business decisions.
Data Integration: Data warehousing integrates data from different sources into a single, unified view, which can help in eliminating data silos and reducing data inconsistencies.
Historical Data Storage: Data warehousing stores historical data, which enables organizations to analyze data trends over time. This can help in identifying patterns and anomalies in the data, which can be used to improve business performance.
Query and Analysis: Data warehousing provides powerful query and analysis capabilities that enable users to explore and analyze data in different ways. This can help in identifying patterns and trends, and can also help in making informed business decisions.
Data Transformation: Data warehousing includes a process of data transformation, which involves cleaning, filtering, and formatting data from various sources to make it consistent and usable. This can help in improving data quality and reducing data inconsistencies.
Data Mining: Data warehousing provides data mining capabilities, which enable organizations to discover hidden patterns and relationships in their data. This can help in identifying new opportunities, predicting future trends, and mitigating risks.
Data Security: Data warehousing provides robust data security features, such as access controls, data encryption, and data backups, which ensure that the data is secure and protected from unauthorized access.
Advantages of Data Warehousing
Intelligent Decision-Making: With centralized data in warehouses, decisions may be made more quickly and intelligently.
Business Intelligence: Provides strong operational insights through business intelligence.
Historical Analysis: Predictions and trend analysis are made easier by storing past data.
Data Quality: Guarantees data quality and consistency for trustworthy reporting.
Scalability: Capable of managing massive data volumes and expanding to meet changing requirements.
Effective Queries: Fast and effective data retrieval is made possible by an optimized structure.
Cost reductions: Data warehousing can result in cost savings over time by reducing data management procedures and increasing overall efficiency, even when there are setup costs initially.
Data security: Data warehouses employ security protocols to safeguard confidential information, guaranteeing that only authorized personnel are granted access to certain data.
Disadvantages of Data Warehousing
Cost: Building a data warehouse can be expensive, requiring significant investments in hardware, software, and personnel.
Complexity: Data warehousing can be complex, and businesses may need to hire specialized personnel to manage the system.
Time-consuming: Building a data warehouse can take a significant amount of time, requiring businesses to be patient and committed to the process.
Data integration challenges: Data from different sources can be challenging to integrate, requiring significant effort to ensure consistency and accuracy.
Data security: Data warehousing can pose data security risks, and businesses must take measures to protect sensitive data from unauthorized access or breaches.
There can be many more applications in different sectors like E-Commerce, telecommunications, Transportation Services, Marketing and Distribution, Healthcare, and Retail.
A data warehouse has a number of components viz. ETL technology, ODS (operational data stores) , data mart etc. A basic data warehouse has data sources, warehouse and users. To process the operational data before it can be entered into data warehouse, the data can be placed on staging area.
To customize the data in the data warehouse, one can use data marts that vary with each function of the business. For example, data mart sales, data mart inventory etc.

A data warehouse uses ETL technology which constitutes the processes of extraction, transformation and loading of data. Application data from the legacy source systems is transferred using ETL that leads to corporate data.
Different processes are done using ETL technology viz. logical conversion of data, verification of domain, conversion of one DBMS to another, creation of default values when needed, summarization of data, addition of time values to the data key, restructuring of data key, merging records and deletion of extraneous or redundant data.
ODS stands for Operational Data Store. It is a place where online updation of integrated data is done using OLTP (Online Transaction Processing) response time. Application data is transferred to ODS using ETL which produces data in integrated format. It involves high-performance processing and update processing.
Data mart is where the end user has direct access and control of his or her analytical data. There are different data marts according to the different departments viz. finance data mart, marketing data mart, sales data mart, etc. Data mart has less data than data warehouse. It contains a significant amount of aggregated and summarized data.
Continue reading the next tutorial for architecture environment, monitoring of data warehouse, structure of data warehouse, granularity of data warehouse, structure and components of data warehouse.
In the complex world of data management, having a clear understanding of concepts like ETL, ODS, and Data Marts is crucial. These tools and methodologies enable us to handle vast volumes of data, streamlining the process of extracting, transforming, and loading it where needed. This can lead to more efficient and informed decision-making processes within an organization. In this journey of exploring data warehousing, we’ve scratched the surface of its potential, but there is so much more to discover. As we move deeper into the digital age, the role of data warehousing will continue to evolve, becoming an even more integral part of how businesses operate and strategize. Stay curious and keep learning because the world of data warehousing is vast and continually evolving.
Architecture is the proper arrangement of the elements. We build a data warehouse with software and hardware components. To suit the requirements of our organizations, we arrange these building we may want to boost up another part with extra tools and services. All of these depends on our circumstances.

The figure shows the essential elements of a typical warehouse. We see the Source Data component shows on the left. The Data staging element serves as the next building block. In the middle, we see the Data Storage component that handles the data warehouses data. This element not only stores and manages the data; it also keeps track of data using the metadata repository. The Information Delivery component shows on the right consists of all the different ways of making the information from the data warehouses available to the users.
Source data coming into the data warehouses may be grouped into four broad categories:
Production Data: This type of data comes from the different operating systems of the enterprise. Based on the data requirements in the data warehouse, we choose segments of the data from the various operational modes.
ADVERTISEMENT
Internal Data: In each organization, the client keeps their "private" spreadsheets, reports, customer profiles, and sometimes even department databases. This is the internal data, part of which could be useful in a data warehouse.
Archived Data: Operational systems are mainly intended to run the current business. In every operational system, we periodically take the old data and store it in achieved files.
External Data: Most executives depend on information from external sources for a large percentage of the information they use. They use statistics associating to their industry produced by the external department.
Data staging in a data warehouse refers to the intermediate storage area where data is temporarily held and processed before being moved to its final destination, such as a data warehouse or data mart12. This area is crucial for the Extract, Transform, Load (ETL) process, which involves:
The staging area acts as a buffer zone where data can be cleansed, transformed, and consolidated from different sources3. This helps ensure that only high-quality, ready-to-analyze data enters the data warehouse, leading to more accurate and reliable insights4.
Would you like to know more about any specific aspect of data staging
After we have been extracted data from various operational systems and external sources, we have to prepare the files for storing in the data warehouse. The extracted data coming from several different sources need to be changed, converted, and made ready in a format that is relevant to be saved for querying and analysis.
We will now discuss the three primary functions that take place in the staging area.

1) Data Extraction: This method has to deal with numerous data sources. We have to employ the appropriate techniques for each data source.
ADVERTISEMENT
2) Data Transformation: As we know, data for a data warehouse comes from many different sources. If data extraction for a data warehouse posture big challenges, data transformation present even significant challenges. We perform several individual tasks as part of data transformation.
First, we clean the data extracted from each source. Cleaning may be the correction of misspellings or may deal with providing default values for missing data elements, or elimination of duplicates when we bring in the same data from various source systems.
Standardization of data components forms a large part of data transformation. Data transformation contains many forms of combining pieces of data from different sources. We combine data from single source record or related data parts from many source records.
On the other hand, data transformation also contains removal of source data that is not useful and separating outsource records into new combinations. Sorting and merging of data take place on a large scale in the data staging area. When the data transformation function ends, we have a collection of integrated data that is cleaned, standardized, and summarized.
3) Data Loading: Two distinct categories of tasks form data loading functions. When we complete the structure and construction of the data warehouse and go live for the first time, we do the initial loading of the information into the data warehouse storage. The initial load moves high volumes of data using up a substantial amount of time.
Data storage for the data warehousing is a split repository. The data repositories for the operational systems generally include only the current data. Also, these data repositories include the data structured in highly normalized for fast and efficient processing.
The information delivery element is used to enable the process of subscribing for data warehouse files and having it transferred to one or more destinations according to some customer-specified scheduling algorithm.
ADVERTISEMENT

Metadata in a data warehouse is equal to the data dictionary or the data catalog in a database management system. In the data dictionary, we keep the data about the logical data structures, the data about the records and addresses, the information about the indexes, and so on.
It includes a subset of corporate-wide data that is of value to a specific group of users. The scope is confined to particular selected subjects. Data in a data warehouse should be a fairly current, but not mainly up to the minute, although development in the data warehouse industry has made standard and incremental data dumps more achievable. Data marts are lower than data warehouses and usually contain organization. The current trends in data warehousing are to developed a data warehouse with several smaller related data marts for particular kinds of queries and reports.
The management and control elements coordinate the services and functions within the data warehouse. These components control the data transformation and the data transfer into the data warehouse storage. On the other hand, it moderates the data delivery to the clients. Its work with the database management systems and authorizes data to be correctly saved in the repositories. It monitors the movement of information into the staging method and from there into the data warehouses storage itself.
Data warehouse architecture is a complex system designed to store, manage, and analyze large volumes of data from various sources. It typically consists of several key components and can be structured in different tiers. Here’s a detailed explanation of the architecture and its components:
Here’s a simplified diagram to illustrate the components and their interactions:
+------------------+ +------------------+ +------------------+
| Data Sources | | Staging Area | | Data Warehouse |
| | | | | |
| (Databases, | | (Temporary | | (Central |
| Flat Files, | --> | Storage) | --> | Repository) |
| Web Services) | | | | |
+------------------+ +------------------+ +------------------+
| | |
| | |
v v v
+------------------+ +------------------+ +------------------+
| ETL | | Data Marts | | Metadata |
| (Extract, | | (Departmental | | (Data About |
| Transform, | --> | Subsets) | --> | Data) |
| Load) | | | | |
+------------------+ +------------------+ +------------------+
| | |
| | |
v v v
+------------------+ +------------------+ +------------------+
| Query Tools | | Data Warehouse | | Data Warehouse |
| (SQL, OLAP, | --> | Bus Architecture| --> | Bus Architecture|
| Visualization) | | | | |
+------------------+ +------------------+ +------------------+
This diagram shows the flow of data from various sources through the ETL process, into the staging area, and finally into the data warehouse. Data marts and metadata support specific business needs, while query tools enable users to interact with the data.
Data Warehouse queries are complex because they involve the computation of large groups of data at summarized levels.
It may require the use of distinctive data organization, access, and implementation method based on multidimensional views.
Performing OLAP queries in operational database degrade the performance of functional tasks.
Data Warehouse is used for analysis and decision making in which extensive database is required, including historical data, which operational database does not typically maintain.
The separation of an operational database from data warehouses is based on the different structures and uses of data in these systems.
|
Database |
Data Warehouse |
|
1. It is used for Online Transactional Processing (OLTP) but can be used for other objectives such as Data Warehousing. This records the data from the clients for history. |
1. It is used for Online Analytical Processing (OLAP). This reads the historical information for the customers for business decisions. |
|
2. The tables and joins are complicated since they are normalized for RDBMS. This is done to reduce redundant files and to save storage space. |
2. The tables and joins are accessible since they are de-normalized. This is done to minimize the response time for analytical queries. |
|
3. Data is dynamic |
3. Data is largely static |
|
4. Entity: Relational modeling procedures are used for RDBMS database design. |
4. Data: Modeling approach are used for the Data Warehouse design. |
|
5. Optimized for write operations. |
5. Optimized for read operations. |
|
6. Performance is low for analysis queries. |
6. High performance for analytical queries. |
|
7. The database is the place where the data is taken as a base and managed to get available fast and efficient access. |
7. Data Warehouse is the place where the application data is handled for analysis and reporting objectives. |
Because the two systems provide different functionalities and require different kinds of data, it is necessary to maintain separate databases.
Schema is a logical description of the entire database. It includes the name and description of records of all record types including all associated data-items and aggregates. Much like a database, a data warehouse also requires to maintain a schema. A database uses relational model, while a data warehouse uses Star, Snowflake, and Fact Constellation schema. In this chapter, we will discuss the schemas used in a data warehouse.
Star Schema
A star schema is the elementary form of a dimensional model, in which data are organized into facts and dimensions. A fact is an event that is counted or measured, such as a sale or log in. A dimension includes reference data about the fact, such as date, item, or customer.
A star schema is a relational schema where a relational schema whose design represents a multidimensional data model. The star schema is the explicit data warehouse schema. It is known as star schema because the entity-relationship diagram of this schemas simulates a star, with points, diverge from a central table. The center of the schema consists of a large fact table, and the points of the star are the dimension tables.


Note − Each dimension has only one dimension table and each table holds a set of attributes. For example, the location dimension table contains the attribute set {location_key, street, city, province_or_state,country}. This constraint may cause data redundancy.
Features of The star schema
The star schema is intensely suitable for data warehouse database design because of the following features:
Star Schemas are easy for end-users and application to understand and navigate. With a well-designed schema, the customer can instantly analyze large, multidimensional data sets.
The main advantage of star schemas in a decision-support environment are:

A star schema database has a limited number of table and clear join paths, the query run faster than they do against OLTP systems. Small single-table queries, frequently of a dimension table, are almost instantaneous. Large join queries that contain multiple tables takes only seconds or minutes to run.
In a star schema database design, the dimension is connected only through the central fact table. When the two-dimension table is used in a query, only one join path, intersecting the fact tables, exist between those two tables. This design feature enforces authentic and consistent query results.
Structural simplicity also decreases the time required to load large batches of record into a star schema database. By describing facts and dimensions and separating them into the various table, the impact of a load structure is reduced. Dimension table can be populated once and occasionally refreshed. We can add new facts regularly and selectively by appending records to a fact table.
A star schema has referential integrity built-in when information is loaded. Referential integrity is enforced because each data in dimensional tables has a unique primary key, and all keys in the fact table are legitimate foreign keys drawn from the dimension table. A record in the fact table which is not related correctly to a dimension cannot be given the correct key value to be retrieved.
A star schema is simple to understand and navigate, with dimensions joined only through the fact table. These joins are more significant to the end-user because they represent the fundamental relationship between parts of the underlying business. Customer can also browse dimension table attributes before constructing a query.
There is some condition which cannot be meet by star schemas like the relationship between the user, and bank account cannot describe as star schema as the relationship between them is many to many.
Example: Suppose a star schema is composed of a fact table, SALES, and several dimension tables connected to it for time, branch, item, and geographic locations.
The TIME table has a column for each day, month, quarter, and year. The ITEM table has columns for each item_Key, item_name, brand, type, supplier_type. The BRANCH table has columns for each branch_key, branch_name, branch_type. The LOCATION table has columns of geographic data, including street, city, state, and country.

In this scenario, the SALES table contains only four columns with IDs from the dimension tables, TIME, ITEM, BRANCH, and LOCATION, instead of four columns for time data, four columns for ITEM data, three columns for BRANCH data, and four columns for LOCATION data. Thus, the size of the fact table is significantly reduced. When we need to change an item, we need only make a single change in the dimension table, instead of making many changes in the fact table.
We can create even more complex star schemas by normalizing a dimension table into several tables. The normalized dimension table is called a Snowflake.
---------------------------------------------
Sales_Amount, Quantity_Sold, Product_ID, and Date_ID.Product_ID, Product_Name, Category, and Brand.For example, in a sales data warehouse, the fact table might record each sale’s amount and quantity, while dimension tables provide details about the products sold, the time of sale, and the customers.
The following are some of the characteristics of a fact table:
The granularity of a fact table is a common way to describe it. The grain of a fact table refers to the most basic level at which the facts can be defined. For example, the grain of a sales fact table might be "sales volume by day by-product by the shop," meaning that each entry in the table is uniquely identified by a day, product, and shop. Other dimensions, such as location or region, may also be included in the fact table, but they do not contribute to the uniqueness of the entries. These "affiliate dimensions" can provide additional information to slice and dice, but they usually provide insights at a higher level of aggregation (since a region contains many stores).
Dimension tables contain descriptions of the objects in a fact table and provide information about dimensions such as values, characteristics, and keys.
To understand this better, let us look at some characteristics of a Dimension Table.
The following are some of the characteristics of a dimension table:
Now that we have a general understanding of fact and dimension tables, let us understand the key differences between these two types of tables in a data warehouse.
Snowflake Schema
A snowflake schema is equivalent to the star schema. "A schema is known as a snowflake if one or more dimension tables do not connect directly to the fact table but must join through other dimension tables."
The snowflake schema is an expansion of the star schema where each point of the star explodes into more points. It is called snowflake schema because the diagram of snowflake schema resembles a snowflake. Snowflaking is a method of normalizing the dimension tables in a STAR schemas. When we normalize all the dimension tables entirely, the resultant structure resembles a snowflake with the fact table in the middle.
Snowflaking is used to develop the performance of specific queries. The schema is diagramed with each fact surrounded by its associated dimensions, and those dimensions are related to other dimensions, branching out into a snowflake pattern.
The snowflake schema consists of one fact table which is linked to many dimension tables, which can be linked to other dimension tables through a many-to-one relationship. Tables in a snowflake schema are generally normalized to the third normal form. Each dimension table performs exactly one level in a hierarchy.

Note − Due to normalization in the Snowflake schema, the redundancy is reduced and therefore, it becomes easy to maintain and the save storage space.
xample: Figure shows a snowflake schema with a Sales fact table, with Store, Location, Time, Product, Line, and Family dimension tables. The Market dimension has two dimension tables with Store as the primary dimension table, and Location as the outrigger dimension table. The product dimension has three dimension tables with Product as the primary dimension table, and the Line and Family table are the outrigger dimension tables.

A star schema store all attributes for a dimension into one denormalized table. This needed more disk space than a more normalized snowflake schema. Snowflaking normalizes the dimension by moving attributes with low cardinality into separate dimension tables that relate to the core dimension table by using foreign keys. Snowflaking for the sole purpose of minimizing disk space is not recommended, because it can adversely impact query performance.
In snowflake, schema tables are normalized to delete redundancy. In snowflake dimension tables are damaged into multiple dimension tables.
A snowflake schema is designed for flexible querying across more complex dimensions and relationships. It is suitable for many to many and one to many relationships between dimension levels.
Advantage of Snowflake Schema
Disadvantage of Snowflake Schema
----------------------------------------------------
Fact Constellation Schema
A Fact constellation means two or more fact tables sharing one or more dimensions. It is also called Galaxy schema.
Fact Constellation Schema describes a logical structure of data warehouse or data mart. Fact Constellation Schema can design with a collection of de-normalized FACT, Shared, and Conformed Dimension tables.

Fact Constellation Schema is a sophisticated database design that is difficult to summarize information. Fact Constellation Schema can implement between aggregate Fact tables or decompose a complex Fact table into independent simplex Fact tables.

This schema defines two fact tables, sales, and shipping. Sales are treated along four dimensions, namely, time, item, branch, and location. The schema contains a fact table for sales that includes keys to each of the four dimensions, along with two measures: Rupee_sold and units_sold. The shipping table has five dimensions, or keys: item_key, time_key, shipper_key, from_location, and to_location, and two measures: Rupee_cost and units_shipped.
The primary disadvantage of the fact constellation schema is that it is a more challenging design because many variants for specific kinds of aggregation must be considered and selected.

A lookup table is a data structure used to map input values to corresponding output values, effectively replacing runtime computation with a simpler array indexing operation. This can significantly speed up processes, as retrieving a value from memory is often faster than performing complex calculations or input/output operations1.
Key Points about Lookup Tables:
Example in Data Warehousing:
In data warehousing, lookup tables are often used to store reference data. For instance, a lookup table might contain detailed information about customers, such as their addresses, cities, and zip codes. This table can be referenced by other tables using a key column
ADVERTISEMENT


Let's see the differentiate between Star and Snowflake Schema.


|
Basis for Comparison |
Star Schema |
Snowflake Schema |
|
Ease of Maintenance/change |
It has redundant data and hence less easy to maintain/change |
No redundancy and therefore more easy to maintain and change |
|
Ease of Use |
Less complex queries and simple to understand |
More complex queries and therefore less easy to understand |
|
Parent table |
In a star schema, a dimension table will not have any parent table |
In a snowflake schema, a dimension table will have one or more parent tables |
|
Query Performance |
Less number of foreign keys and hence lesser query execution time |
More foreign keys and thus more query execution time |
|
Normalization |
It has De-normalized tables |
It has normalized tables |
|
Type of Data Warehouse |
Good for data marts with simple relationships (one to one or one to many) |
Good to use for data warehouse core to simplify complex relationships (many to many) |
|
Joins |
Fewer joins Higher |
number of joins |
|
Dimension Table |
It contains only a single dimension table for each dimension |
It may have more than one dimension table for each dimension |
|
Hierarchies |
Hierarchies for the dimension are stored in the dimensional table itself in a star schema |
Hierarchies are broken into separate tables in a snowflake schema. These hierarchies help to drill down the information from topmost hierarchies to the lowermost hierarchies. |
|
When to use |
When the dimensional table contains less number of rows, we can go for Star schema. |
When dimensional table store a huge number of rows with redundancy information and space is such an issue, we can choose snowflake schema to store space. |
|
Data Warehouse system |
Work best in any data warehouse/ data mart |
Better for small data warehouse/data mart. |
Data warehouses often contain very large tables and require techniques both for managing these large tables and for providing good query performance across them. An important tool for achieving this, as well as enhancing data access and improving overall application performance is partitioning.
Partitioning offers support for very large tables and indexes by letting you decompose them into smaller and more manageable pieces called partitions. This support is especially important for applications that access tables and indexes with millions of rows and many gigabytes of data. Partitioned tables and indexes facilitate administrative operations by enabling these operations to work on subsets of data. For example, you can add a new partition, organize an existing partition, or drop a partition with minimal to zero interruption to a read-only application.
Partitioning can help you tune SQL statements to avoid unnecessary index and table scans (using partition pruning). It also enables you to improve the performance of massive join operations when large amounts of data (for example, several million rows) are joined together by using partition-wise joins. Finally, partitioning data greatly improves manageability of very large databases and dramatically reduces the time required for administrative tasks such as backup and restore.
When adding or creating a partition, you have the option of deferring the segment creation until the data is first inserted, which is particularly valuable when installing applications that have a large footprint.
Granularity in a partitioning scheme can be easily changed by splitting or merging partitions. Thus, if a table's data is skewed to fill some partitions more than others, the ones that contain more data can be split to achieve a more even distribution. Partitioning also enables you to swap partitions with a table. By being able to easily add, remove, or swap a large amount of data quickly, swapping can be used to keep a large amount of data that is being loaded inaccessible until loading is completed, or can be used as a way to stage data between different phases of use. Some examples are current day's transactions or online archives.
A good starting point for considering partitioning strategies is to use the partitioning advice within the SQL Access Advisor, part of the Tuning Pack. The SQL Access Advisor offers both graphical and command-line interfaces.
A complementary approach that is commonly used with partitioning is parallel execution, which speeds up long-running queries, ETL, and some other operations. For data warehouses with very high loads of parallel statements, parallel statement queuing can be used to automatically manage the parallel statements.
Partitioning is done to enhance performance and facilitate easy management of data. Partitioning also helps in balancing the various requirements of the system. It optimizes the hardware performance and simplifies the management of data warehouse by partitioning each fact table into multiple separate partitions. In this chapter, we will discuss different partitioning strategies.
Why is it Necessary to Partition?
Partitioning can have many advantages, but these are some of the most common reasons that developers and architects choose to partition their data:
Data partitioning can improve scalability because running a database on a single piece of hardware is inherently limited. While it is possible to improve the capability of a single database server by upgrading its components — this is called vertical scaling — this approach has diminishing returns in terms of performance and inherent limitations in terms of networking (i.e., users located somewhere geographically far from the database will experience more latency). It also tends to be more expensive.
However, if data is partitioned, then the database can be scaled horizontally, meaning that additional servers can be added. This is often a more economical way to keep up with growing demand, and it also allows for the possibility of locating different partitions in different geographic areas, ensuring that users across the globe can enjoy a low-latency application experience.
Data partitioning can improve availability because running a database on a single piece of hardware means your database has a single point of failure. If the database server goes down, your entire database — and by extension, your application — is offline.
In contrast, spreading the data across multiple partitions allows each partition to be stored on a separate server. The same data can also be replicated onto multiple servers, allowing the entire database to remain available to your application (and its users) even if a server goes offline.
Data partitioning can improve performance in a variety of different ways depending on how you choose to deploy and configure your partitions. One common way that partitioning improves performance is by reducing contention — in other words, by spreading the load of user requests across multiple servers so that no single piece of hardware is being asked to do too much at once.
Or another example: you might choose to partition your data in different geographic regions based on user location so that the data that users access most frequently is located somewhere close to them. This would reduce the amount of latency they experience when using your application.
There are other potential advantages to data partitioning, but which specific advantages you might anticipate from partitioning your data will depend on the type of partitioning you choose, as well as the configuration options you select, the type of database you’re using, and more.
Partitioning is important for the following reasons −
For Easy Management
The fact table in a data warehouse can grow up to hundreds of gigabytes in size. This huge size of fact table is very hard to manage as a single entity. Therefore it needs partitioning.
To Assist Backup/Recovery
If we do not partition the fact table, then we have to load the complete fact table with all the data. Partitioning allows us to load only as much data as is required on a regular basis. It reduces the time to load and also enhances the performance of the system.
Note − To cut down on the backup size, all partitions other than the current partition can be marked as read-only. We can then put these partitions into a state where they cannot be modified. Then they can be backed up. It means only the current partition is to be backed up.
To Enhance Performance
By partitioning the fact table into sets of data, the query procedures can be enhanced. Query performance is enhanced because now the query scans only those partitions that are relevant. It does not have to scan the whole data.
Horizontal Partitioning
There are various ways in which a fact table can be partitioned. In horizontal partitioning, we have to keep in mind the requirements for manageability of the data warehouse.
Partitioning by Time into Equal Segments
In this partitioning strategy, the fact table is partitioned on the basis of time period. Here each time period represents a significant retention period within the business. For example, if the user queries for month to date data then it is appropriate to partition the data into monthly segments. We can reuse the partitioned tables by removing the data in them.
Partition by Time into Different-sized Segments
This kind of partition is done where the aged data is accessed infrequently. It is implemented as a set of small partitions for relatively current data, larger partition for inactive data.

Points to Note
Partition on a Different Dimension
The fact table can also be partitioned on the basis of dimensions other than time such as product group, region, supplier, or any other dimension. Let's have an example.
Suppose a market function has been structured into distinct regional departments like on a state by state basis. If each region wants to query on information captured within its region, it would prove to be more effective to partition the fact table into regional partitions. This will cause the queries to speed up because it does not require to scan information that is not relevant.
Points to Note
Note − We recommend to perform the partition only on the basis of time dimension, unless you are certain that the suggested dimension grouping will not change within the life of the data warehouse.
Partition by Size of Table
When there are no clear basis for partitioning the fact table on any dimension, then we should partition the fact table on the basis of their size. We can set the predetermined size as a critical point. When the table exceeds the predetermined size, a new table partition is created.
Points to Note
Partitioning Dimensions
If a dimension contains large number of entries, then it is required to partition the dimensions. Here we have to check the size of a dimension.
Consider a large design that changes over time. If we need to store all the variations in order to apply comparisons, that dimension may be very large. This would definitely affect the response time.
Round Robin Partitions
In the round robin technique, when a new partition is needed, the old one is archived. It uses metadata to allow user access tool to refer to the correct table partition.
This technique makes it easy to automate table management facilities within the data warehouse.
Vertical Partition
Vertical partitioning, splits the data vertically. The following images depicts how vertical partitioning is done.

Vertical partitioning can be performed in the following two ways −
Normalization
Normalization is the standard relational method of database organization. In this method, the rows are collapsed into a single row, hence it reduce space. Take a look at the following tables that show how normalization is performed.
Table before Normalization
|
Product_id |
Qty |
Value |
sales_date |
Store_id |
Store_name |
Location |
Region |
|
30 |
5 |
3.67 |
3-Aug-13 |
16 |
sunny |
Bangalore |
S |
|
35 |
4 |
5.33 |
3-Sep-13 |
16 |
sunny |
Bangalore |
S |
|
40 |
5 |
2.50 |
3-Sep-13 |
64 |
san |
Mumbai |
W |
|
45 |
7 |
5.66 |
3-Sep-13 |
16 |
sunny |
Bangalore |
S |
Table after Normalization
|
Store_id |
Store_name |
Location |
Region |
|
|
16 |
sunny |
Bangalore |
W |
|
|
64 |
san |
Mumbai |
S |
|
|
Product_id |
Quantity |
Value |
sales_date |
Store_id |
|
30 |
5 |
3.67 |
3-Aug-13 |
16 |
|
35 |
4 |
5.33 |
3-Sep-13 |
16 |
|
40 |
5 |
2.50 |
3-Sep-13 |
64 |
|
45 |
7 |
5.66 |
3-Sep-13 |
16 |
Row Splitting
Row splitting tends to leave a one-to-one map between partitions. The motive of row splitting is to speed up the access to large table by reducing its size.
Note − While using vertical partitioning, make sure that there is no requirement to perform a major join operation between two partitions.
Identify Key to Partition
It is very crucial to choose the right partition key. Choosing a wrong partition key will lead to reorganizing the fact table. Let's have an example. Suppose we want to partition the following table.
Account_Txn_Table
transaction_id
account_id
transaction_type
value
transaction_date
region
branch_name
We can choose to partition on any key. The two possible keys could be
Suppose the business is organized in 30 geographical regions and each region has different number of branches. That will give us 30 partitions, which is reasonable. This partitioning is good enough because our requirements capture has shown that a vast majority of queries are restricted to the user's own business region.
If we partition by transaction_date instead of region, then the latest transaction from every region will be in one partition. Now the user who wants to look at data within his own region has to query across multiple partitions.
Vertical partitioning is when the table is split by columns, with different columns stored on different partitions.
In vertical partitioning, we might split the table above up into two partitions, one with the id, username, and city columns, and one with the id and balance columns, like so.
Partition 1
|
id |
username |
city |
|
1 |
theo |
london |
|
2 |
kee |
portland |
|
3 |
julian |
new york |
|
4 |
jasper |
boston |
|
… |
… |
… |
|
9998 |
syd |
shanghai |
|
9999 |
nigel |
santiago |
|
10000 |
marichka |
london |
|
10001 |
luke |
new york |
Partition 2
|
id |
balance |
|
1 |
213 |
|
2 |
75444 |
|
3 |
645 |
|
4 |
342 |
|
… |
… |
|
9998 |
5145 |
|
9999 |
4350 |
|
10000 |
873 |
|
10001 |
2091 |
Generally speaking, the reason to partition the data vertically is that the data on the different partitions is used differently, and it thus makes sense to store it on different machines.
Here, for example, it might be the case that the balance column is updated very frequently, whereas the username and city columns are relatively static. In that case, it could make sense to partition the data vertically and locate Partition 2 on a high-performance, high-throughput server, while the slower-moving Partition 1 data could be stored on less performant machines with little impact on the user’s application experience.
Horizontal partitioning is when the table is split by rows, with different ranges of rows stored on different partitions.
To horizontally partition our example table, we might place the first 500 rows on the first partition and the rest of the rows on the second, like so:
Partition 1
|
id |
username |
city |
balance |
|
1 |
theo |
london |
213 |
|
2 |
kee |
portland |
75444 |
|
3 |
julian |
new york |
645 |
|
4 |
jasper |
boston |
342 |
|
… |
… |
… |
… |
|
500 |
alfonso |
mex. cityc |
435435 |
Partition 2
|
id |
username |
city |
balance |
|
501 |
tim |
l.a. |
24235 |
|
… |
… |
… |
… |
|
9998 |
syd |
shanghai |
5145 |
|
9999 |
nigel |
santiago |
4350 |
|
10000 |
marichka |
london |
873 |
|
10001 |
luke |
new york |
2091 |
Horizontal partitioning is typically chosen to improve performance and scalability. When running a database on a single machine, it can sometimes make sense to partition tables to (for example) improve the performance of specific, frequently used queries against that data.
Often, however, horizontal partitioning splits tables across multiple servers for the purposes of increasing scalability. This is called sharding.
Sharding is a common approach employed by companies that need to scale a relational database. Vertical scaling — upgrading the hardware on the database server — can only go so far. At a certain point, adding additional machines becomes necessary. But splitting the database load between multiple servers means splitting the data itself between servers. Generally, this is accomplished by splitting the table into ranges of rows as illustrated above, and then spreading those ranges, called shards, across the different servers.
Since the load of requests can be spread across different shards depending on the data being queried, sharding the database can improve overall performance. As new data is added, new shards can be created — although this often involves significant manual work — to keep up with the increasing size of the workload coming from the application.
Difference between Vertical and Horizontal Partitioning
Here’s a comparison of the two partitioning methods:
|
Feature |
Vertical Partitioning |
Horizontal Partitioning |
|
Definition |
Dividing a table into smaller tables based on columns. |
Dividing a table into smaller tables based on rows (usually ranges of rows). |
|
Purpose |
Reduce the number of columns in a table to improve query performance and reduce I/O. |
Divide a table into smaller tables to manage large volumes of data efficiently. |
|
Data distribution |
Columns with related data are placed together in the same table. |
Rows with related data (typically based on a range or a condition) are placed together in the same table. |
|
Query performance |
Improves query performance when queries only involve specific columns that are part of a partition. |
Improves query performance when queries primarily access a subset of rows in a large table. |
|
Maintenance and indexing |
Easier to manage and index specific columns based on their characteristics and access patterns. |
Each partition can be indexed independently, making indexing more efficient. |
|
Joins |
May require joins to combine data from multiple partitions when querying. |
Joins between partitions are typically not needed, as they contain disjoint sets of data. |
|
Data integrity |
Ensuring data consistency across partitions can be more challenging. |
Easier to maintain data integrity, as each partition contains a self-contained subset of data. |
|
Use cases |
Commonly used for tables with a wide range of columns, where not all columns are frequently accessed together. |
Commonly used for tables with a large number of rows, where data can be grouped based on some criteria (e.g., date ranges). |
|
Examples |
Splitting a customer table into one table for personal details and another for transaction history. |
Partitioning a large sales order table by date, with each partition containing orders from a specific month or year. |
Partitioning in a data warehouse is a technique used to divide large tables into smaller, more manageable pieces called partitions. This approach significantly enhances performance, manageability, and scalability of the data warehouse. Here are some key points about partitioning:
Partitioning strategies in a data warehouse are essential for managing large datasets efficiently and improving query performance. Here are the main partitioning strategies in detail:
Range partitioning divides data based on a range of values, such as dates or numerical ranges. Each partition holds a specific range of data.
List partitioning assigns data to partitions based on a list of discrete values. Each partition contains rows that match one of the specified values.
Hash partitioning distributes data evenly across partitions using a hash function. This method ensures an even distribution of data, which can help balance the load.
Composite partitioning combines two or more partitioning methods, such as range-hash or range-list partitioning. This approach allows for more complex and flexible partitioning schemes.
Interval partitioning is an extension of range partitioning, where new partitions are automatically created as data arrives, based on a specified interval.
Reference partitioning allows partitioning of a child table based on the partitioning of a parent table, maintaining referential integrity.
What is Metadata?
Metadata is simply defined as data about data. The data that is used to represent other data is known as metadata. For example, the index of a book serves as a metadata for the contents in the book. In other words, we can say that metadata is the summarized data that leads us to detailed data. In terms of data warehouse, we can define metadata as follows.
Note − In a data warehouse, we create metadata for the data names and definitions of a given data warehouse. Along with this metadata, additional metadata is also created for time-stamping any extracted data, the source of extracted data.
Categories of Metadata
Metadata can be broadly categorized into three categories −

Role of Metadata
Metadata has a very important role in a data warehouse. The role of metadata in a warehouse is different from the warehouse data, yet it plays an important role. The various roles of metadata are explained below.
The following diagram shows the roles of metadata.

Metadata Repository
Metadata repository is an integral part of a data warehouse system. It has the following metadata −
Challenges for Metadata Management
The importance of metadata can not be overstated. Metadata helps in driving the accuracy of reports, validates data transformation, and ensures the accuracy of calculations. Metadata also enforces the definition of business terms to business end-users. With all these uses of metadata, it also has its challenges. Some of the challenges are discussed below.
Listed below are the reasons to create a data mart −
Note − Do not data mart for any other reason since the operation cost of data marting could be very high. Before data marting, make sure that data marting strategy is appropriate for your particular solution.
Follow the steps given below to make data marting cost-effective −
In this step, we determine if the organization has natural functional splits. We look for departmental splits, and we determine whether the way in which departments use information tend to be in isolation from the rest of the organization. Let's have an example.
Consider a retail organization, where each merchant is accountable for maximizing the sales of a group of products. For this, the following are the valuable information −
As the merchant is not interested in the products they are not dealing with, the data marting is a subset of the data dealing which the product group of interest. The following diagram shows data marting for different users.

Given below are the issues to be taken into account while determining the functional split −
Note − We need to determine the business benefits and technical feasibility of using a data mart.
We need data marts to support user access tools that require internal data structures. The data in such structures are outside the control of data warehouse but need to be populated and updated on a regular basis.
There are some tools that populate directly from the source system but some cannot. Therefore additional requirements outside the scope of the tool are needed to be identified for future.
Note − In order to ensure consistency of data across all access tools, the data should not be directly populated from the data warehouse, rather each tool must have its own data mart.
There should to be privacy rules to ensure the data is accessed by authorized users only. For example a data warehouse for retail banking institution ensures that all the accounts belong to the same legal entity. Privacy laws can force you to totally prevent access to information that is not owned by the specific bank.
Data marts allow us to build a complete wall by physically separating data segments within the data warehouse. To avoid possible privacy problems, the detailed data can be removed from the data warehouse. We can create data mart for each legal entity and load it via data warehouse, with detailed account data.
Data marts should be designed as a smaller version of starflake schema within the data warehouse and should match with the database design of the data warehouse. It helps in maintaining control over database instances.

The summaries are data marted in the same way as they would have been designed within the data warehouse. Summary tables help to utilize all dimension data in the starflake schema.
The cost measures for data marting are as follows −
Although data marts are created on the same hardware, they require some additional hardware and software. To handle user queries, it requires additional processing power and disk storage. If detailed data and the data mart exist within the data warehouse, then we would face additional cost to store and manage replicated data.
Note − Data marting is more expensive than aggregations, therefore it should be used as an additional strategy and not as an alternative strategy.
A data mart could be on a different location from the data warehouse, so we should ensure that the LAN or WAN has the capacity to handle the data volumes being transferred within the data mart load process.
The extent to which a data mart loading process will eat into the available time window depends on the complexity of the transformations and the data volumes being shipped. The determination of how many data marts are possible depends on −
